



Алексей Благирев
Big data простым языком
Постинформационное общество[3]
Взрывной рост технологий использования данных приблизил человечество к новой модели своей работы – постинформационному обществу.
Звучит слишком заумно? Вообще префикс «пост» уже много где используется: постистория, постмодернизм, постиндустриальное общество и так далее.
Смысл постинформационного общества в том, что полезные знания среди разнообразной информации теперь могут находить алгоритмы, а не люди, которые их спроектировали.
Ну, то есть, учась в школе, ребенок может решать домашнюю работу вместе с алгоритмами, а не с родителями.
А еще с алгоритмами можно анализировать диагнозы множества пациентов или симптомов одновременно, не полагаясь на человеческую экспертизу.
Это реально?
Ага. Google со своим умным «движком» TensorFlow или Яндекс с CatBoost сделали возможным создание уникальных сервисов с использованием данных в домашних условиях (без каких-либо специальных лабораторий).
И чем больше мы используем алгоритмы, тем больше они учатся. Это можно гордо назвать демократизацией – когда всем понемногу достается кусочек счастья.
Демократизация технологий запустила новые процессы по унификации роли человека в процессах обработки, управления данными и развития искусственного интеллекта. Ручной труд стал больше не нужен. Всякие сверки и контроли – работа, которую теперь можно поручать алгоритмам, и они, в отличие от человека, умеют справляться с ней без ошибок.
Даже последний рубеж, которые машины взять никак не могли – тоже покорился. За несколько лет алгоритмы смогли освоить решение ранее сложных творческих и коллаборативных задач. Причем, этот рывок невозможно было спрогнозировать еще пять лет назад.
Такие системы как Alexa, Siri, Алиса и другие, ускоренными темпами захватывают рынок персональных ассистентов.
В 2015 году эксперты даже в своих самых смелых ожиданиях не могли сойтись в том, что алгоритмы смогут пройти этот рубеж всего лишь через год.
Сегодня есть ощущение, что близится еще один большой рывок, и он может произойти в ближайшие несколько лет.
По одной из гипотез им станет трансформация работы с данными для производств. Тогда собираемая информация будет использоваться с целью анализа и выявления аномалий операционного цикла производства, упрощая управление конвейером, будь это надой молока с установленными датчиками на коровах или завод по производству металлической продукции. Я говорю о едином управлении жизненным циклом продукта или услуги, например – локомотива. Компании взаправду разрабатывают единую концепцию жизненного цикла локомотивов и цифровизации депо. Это уже происходит в России.

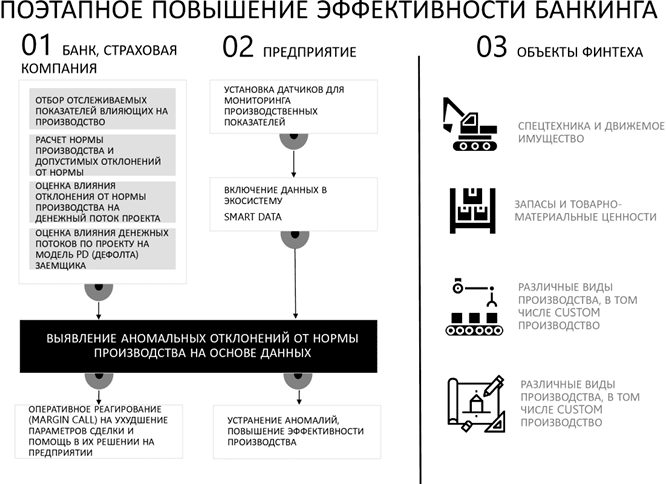
Создание подобных центров управления предприятиями сегодня не имеет технологических барьеров, проблема исключительно в кооперации участников. Решив ее, мир откроет невообразимую возможность создания адаптивной экономики, когда плановые значения заменяются на стандартные нормы производства, которые высчитывают алгоритмы в зависимости от множества факторов.
Но большинство людей все еще мыслит устаревшими категориями.
Для людей, проработавших много лет на производствах, все кажется достаточно понятным и простым. Сначала рисуешь и проектируешь с инженерами деталь, потом готовишь документацию, где прописываешь, как эту деталь обслуживать, потом производишь и, наконец, обслуживаешь.
Казалось бы, все цели ясны, все пути определены – вперед, товарищи!
А на деле все сложнее. Упомянутый выше локомотив может быть старой развалиной без документации. И вот тут людям приходится креативить. Иными словами, инженеры пытаются решить проблему на месте, прямо в депо. Таких примеров много. Что это означает? Только то, что привычного конвейера, который придумал в свое время Генри Форд, больше не существует. Признать это сложно.
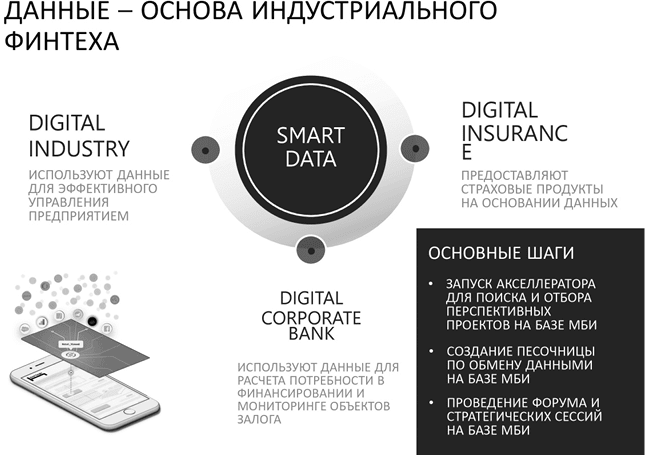
Людям хочется верить, что всем можно управлять, а если запустить какой-нибудь сверхмасштабный проект, то вообще получится все вокруг цифровизировать и изменить. Потоки данных будут передаваться от производства к другим участникам рынка, например к страховой компании, которая будет выписывать страховой продукт, используя данные без выезда специалистов.
Страховая премия в этом случае может быть ниже рынка как минимум на десять процентов, при этом сам продукт будет более маржинален для страхового бизнеса, так как начнет использовать более точную оценку наступления риска, построенную на данных. Аналогичные продукты с использованием данных может предоставлять банковский сектор. Все соединится в единую экосистему обработки информации и извлечения из нее ценности.
Захватывает, не так ли?
Но на практике никакие масштабные программы не работают, потому они медленные и не говорят на одном языке с технологией.
Государство, как и бизнес, тоже движется в сторону повышения роли данных. Но как сравнить, где находится государство с точки зрения роли Больших данных?
В 1965 году ООН ввел разделение на развивающие рынки и развитые страны.
Не важно, что это разделение уже не работает – его опроверг Ханс Рослинг[4]. Важно, что была попытка предложить систему оценки для сравнения экономического развития стран.
Сейчас, конечно, в национальном плане, единых критериев оценок до сих пор не выработано, хотя каждый малозначимый институт развития пытается предложить свою модель оценки для Больших данных. Короче, не понятно, кто где находится и куда идет.
Например, модель зрелости цифрового государства исследовательской компании Gartner, предполагает пять ступеней зрелости, где data-centric государство – это третья средняя ступень в развитии, этап, когда власть понимает, какие данные есть, когда она отладила процессы их получения и управления качеством.
Россия сегодня успешно завершает переход с первой ступени (E-Gov[5]) на вторую – когда для создания новых информационных сервисов федеральные и муниципальные органы власти предоставляют возможность получения открытых данных, хранящихся в государственных учреждениях. Но сами данные еще разрознены, некачественны, и, по сути, пользоваться ими пока что нельзя.
В Министерстве цифрового развития один из важнейших проектов – создание платформы управления классификаторами (для статистики), когда бизнес и общество могут стать основными источниками данных друг для друга. В идеале разработка платформы может устранить разобщенность классификации, например, номенклатуры товаров. Представьте себе, что больше не надо заполнять никакие накладные, таможенные декларации и прочие бумаги, весь товар регистрируется при производстве и отслеживается. Можно забыть про бумагу.
Единые классификаторы товарных позиций позволяют существенно упростить взаимодействие между несколькими торговыми рынками. В какой-то момент классификаторы позволят создать между ними уникальные зоны свободной торговли. Допустим, что вы приехали в аэропорт и идете через «зеленый коридор», вас никто не трогает, а рядом, в «красном коридоре», происходит принудительный досмотр вещей. Мысленно вы улыбаетесь, радуетесь тому, что вас там нет. Представьте, что таким может быть производство, банкинг, страхование и торговля.
Помимо бизнеса или государства, конечно же, данные сами по себе точно так же оказывают непосредственное влияние на рядового пользователя, например, упрощая процедуру идентификации и получения тех или иных сервисов, в том числе и финансовых. Так, можно удаленно открыть банковский счет, используя только биометрические данные и информацию из учетной записи в государственных системах. Вот вам и опять какие-то новые интерфейсы, которые уже вроде как работают. Пора в них разобраться.
В мире давно существует множество платформ, таких как id.me, tupas, bank.id и других, позволяющих использовать единую учетную запись без необходимости хранить десятки паролей.
Эти платформы формируют будущее цифровой идентичности.
С другой стороны, новое общество, которое уже десятилетием пользуется социальными сетями, электронной почтой и мессенджерами, обзавелось уникальными артефактами и привычками, которых нет как в настоящей жизни, так и в юридической практике.
Такие понятия как «лайк», «репост», «шер», «трансляция», оказывают большее влияние на пользователей, чем пощечина. Из-за лайков люди ссорятся, расходятся или строят целые бизнес модели.
Появилось такое явление как «цифровое рабство» которое стало следствием того, что данные пользователей не принадлежат им самим. Во многом это помогло цифровым платформам проектироваться без учета общественного диалога. Но парадокс в том, что такой диалог был невозможен на момент зарождения таких платформ ввиду отсутствия пользовательского опыта по использованию данных у самого общества. Соответственно, нас будут ждать еще и этические дилеммы в отношении тех или иных данных.
Сегодня общество уже переживает рефлексию о том, что такое «хорошо» и что такое «плохо» в отношении своих данных. Что делать можно, а что делать не нужно, даже если это явно не запрещено законом, еще предстоит определить. Определение этой границы в использовании данных откроется в самое ближайшее время.
Необходимо разобраться в совершенно новых явлениях, в том числе таких, как «цифровое бессмертие».
Кто и как может пользоваться данными, если пользователя больше нет среди живых? Стоит ли оставлять его «цифровые следы» во всемирной паутине?
В 2015 году в сети Facebook насчитывалось более пяти миллионов аккаунтов (страниц) людей, которые умерли. Вот вам так называемые цифровые памятники и реквиемы.
В нашей стране, если в табличку с персональными[6] данными добавить отдельное новое поле «дата смерти» и заполнить его, то такие данные перестанут быть персональными по действующему закону. Они более вне законодательного поля.
Или другой случай. Номер мобильного телефона сам по себе не является персональными данными и не защищен законом о персональных данных. Интересно, не правда ли?
С точки зрения регулирования в России сегодня есть базовый минимум по защите информации и прав пользователей, но как это законодательство реально работает по отношению к данным, предстоит открыть каждому индивидуально.
В развитом бизнесе количество информационных систем, хранящих данные пользователей, может исчисляться десятками, а порой и сотнями. Даже если в соответствии с законодательством рядовой пользователь напишет в компанию, которая обрабатывает его персональные данные, обращение с просьбой удалить их и реализовать свое законное право на «забвение»[7], компания не сможет полностью удалить или обезличить данные пользователя в своих системах. Во многом это произойдет из-за недостаточной развитости процессов и решений управления данными, ведь пользовательские данные в большинстве случае разбросаны по системам, не имеющим единой красной кнопки, которая бы могла все замаскировать.
Но существуют и исключения. Например, решение от команды HumanFactorLabs позволяет объединить и связать различные образы, копии и образцы данных о потребителе, клиенте или организации в разных системах, что в нужный момент позволит реализовать право на «забвение» посредством отдельного сервиса.
Регулирование данных в России представляет собой разобщенный процесс, по которому нет единого координирующего органа. Если мы вернемся к праву на «забвение», то существующая статистика обращений в России и за рубежом показывает, что большая часть исков пока проигрывается, да и количество обращений потребителей с исками невелико. Но переломный момент рано или поздно наступит.
Начиная с 2015 года[8] все налоговые агенты стали обязаны указывать в сопроводительных справках при удержании налога информацию об идентификационном номере налогоплательщика (ИНН).
Для справки: организация является налоговым агентом, если платит за кого-то налоги как, скажем, работодатель, который платит за своего сотрудника налог на прибыль, или банк, который удерживает налог, если привлекает депозиты по высокой ставке или решил списать часть задолженности.
Ситуация усложнилась тем, что для финансовых организаций поле «ИНН» не являлось обязательным при выдаче банковского продукта (кредита или депозита). Добавление нового поля требовало организовать доработку всех ключевых банковских систем.
Непредоставление такой информации в Федеральную налоговую службу могло повлечь за собой возможность наложения штрафа на налогового агента в сумме от двухсот тысяч рублей за одну запись[9]. Сумма штрафа в пятьдесят миллионов рублей становилась существенной для ведения бизнеса с данными клиентов.
Таким образом, данные помимо возможности монетизации приводят организацию к риску получения внепланового расхода. Подход для работы с ними усложняется, требуются новые инструменты, новые профессии и новые правила работы с данными.
Данные – это актив, новая нефть, которая еще не имеет всех необходимых дефиниций по правильности или этичности использования.
Кругом только косяки и сложности. Чтобы понимать многообразие всех этих связей, которые появились, нужно обладать определенными навыками работы с данными как с точки зрения технологии, так и с точки зрения буквы закона.
Хочу упомянуть моего друга, Джозефа Маклеода. Он был когда-то UX дизайнером Nokia и является автором концепции Off-boarding. Согласно его парадигме, пользователи в цифровой среде ведут себя уже не так, как на индустриальном рынке. Они перестали бесконечно потреблять.
Информации вокруг стало так много, что внимание пользователей научилось чаще переключаться. Пользователям больше не нужно то, что им предлагали обычно. Капитализм в привычной форме отступает. Жизненный цикл потребителя теперь должен не только уверенно начинаться и поддерживаться, но и завершаться.
Завершение – один из важнейших этапов взаимодействия с пользователем в цифровом мире, но большинство компаний и сервисов не уделяют ему должного внимания, из-за чего данные пользователей по-прежнему остаются в компаниях. Висят незакрытые банковские счета, приходят уведомления о подписках и сервисах, которые уже не интересны клиентам.
Data-driven организации[10]
Если вы работаете с данными, то необходимо помнить, что все новинки и важные изменения в подходах работы с ними всегда отражались в первую очередь в маркетинге или в коммуникации с клиентом, будь то UX-интерфейс или персональное уведомление.
В середине 2000-х, организации, занимающиеся дизайном, провозгласили новую тенденцию data-driven организаций, когда все расположения кнопочек, иконок или иных интерфейсов подчиняются логике работы на основании данных. Так называемый Data-driven Design.

Иными словами, все, что увеличивает конверсию, отражает текущее поведение клиента или потенциального клиента, должно строиться на основании данных и наблюдений. Получается, что все события превращаются в данные, которые ведут к конкретным решениям, так что организация становится дата-центрированной, то есть все решения внутри нее по созданию ценности, запусков продуктов или оптимизации, подчиняются исключительно данным.
Впервые термин data-driven был представлен в 1990 году Тимом Джонсоном[11], преподавателем School of English в Университете Бирмингема. Он предположил, что в основе любого языка находятся определенные общие понятия, «corpus»[12], на основе которых можно строить зависимость и исследовать лингвистику языка. Для своего исследования Джонсон использовал Международную базу лингвистических данных Бирмингемского университета (COBUILT). Эта работа легла в основу создания и описания корпусной лингвистики, что, в свою очередь, позднее повлечет за собой создание машиночитаемой лингвистики, использование Скрытых Марковских Моделей[13] и создание алгоритмов распознавания образов и текста.
Впоследствии централизация решений через данные распространилась на все ключевые бизнес-процессы без исключения и привела к новым формам внутренней работы организаций – data-driven organization.
Data-driven организации – это такие компании, в которых все внутренние процессы и большинство решений вокруг них строятся исключительно на основании данных. Вначале 2000-х ряд компаний провозгласили себя data-driven: Google, Facebook и другие.
Развитие новой формы кооперации человека с использованием данных немедленно натолкнулось на один из первых барьеров на пути своего становления.
Им стал синдром HYPPO.
В 1963 году психолог из Йельского Университета, Стэнли Милгрэм, поставил эксперимент по социальной психологии, который описал позднее в статье «Подчинение: исследование поведения». Суть эксперимента сводилась к тому, что испытуемому предлагали стать на время Учителем и «помочь» Ученику (который был актером) выучить ряд слов и сочетаний. Экспериментатор дал Учителю указание, в случае ошибки, каждый раз бить током Ученика. При этом, каждая новая ошибка влекла за собой увеличение силы тока, вплоть до смертельно опасной. Ученик, в свою очередь, имитировал боль от тока, а Экспериментатор заставлял Учителя продолжать эксперимент, несмотря ни на какие возгласы со стороны Ученика.
До начала эксперимента Стэнли Милгрэм попросил большинство коллег, с которыми работал, оценить, сколько испытуемых дойдет до конца эксперимента. Большинство сошлось на двадцати процентах, но на практике все вышло ровным счетом наоборот. Менее двадцати процентов участников отказались продолжать эксперимент, а подавляющее большинство прошло его до конца. Этот психологический эксперимент показал чрезвычайно сильно выраженную готовность здоровых и нормальных взрослых людей достаточно долго следовать указаниям Экспериментатора (авторитета).
Причем же здесь данные?
Обратимся к евангелисту по цифровому маркетингу Google, Авинаш Кошик, который впервые ввел термин HYPPO в своей книге Web analytics: An Hour a Day.
HYPPO – означает мнение самого высокооплачиваемого человека в комнате (Highest Paid Person Opinion). Когда в комнате, где принимается решение, есть человек, который получает больше всех, то, скорее всего, его авторитет будет ключевым при формировании конечного решения.
Во многом такие решения могут противоречить тем, которые принимались на основании данных. Первые решения субъективны и, в конечном счете, преследуют личную выгоду, принося скрытый ущерб обществу. И как же быть? Ответ может лежать в плоскости деперсонификации принимаемых решений посредством анализа получаемых данных. Данные позволяют отказаться от эмоций и личной заинтересованности при анализе получаемых фактов.
Для этого процесс подготовки отчетности требует определенной реорганизации, как в прочем и самой организации.