



Джейд Картер
Обработка больших данных
Слово от автора
В современном мире данных существует огромное количество информации, которая поступает к нам со всех сторон. Начиная от записей в социальных сетях и заканчивая данными с промышленных сенсоров, объемы информации, с которыми нам приходится работать, растут с невиданной скоростью. Именно в этом контексте технологии больших данных выходят на первый план, открывая перед нами новые возможности для анализа, прогнозирования и принятия решений.
Эта книга родилась из моего стремления помочь вам не просто понять, но и эффективно применять технологии больших данных в ваших проектах и бизнесе. Я постарался охватить весь спектр тем, начиная с основ и заканчивая продвинутыми техниками и реальными примерами. Мы начнем с изучения того, какие преимущества могут дать большие данные вашей организации и с какими вызовами вам предстоит столкнуться. Затем мы детально разберем архитектуру и экосистему Apache Hadoop – одной из ключевых платформ для работы с большими данными. Вы узнаете, как развернуть и настроить кластер Hadoop, и научитесь решать практические задачи с его помощью.
Особое внимание в книге уделено Apache Spark, который позволяет значительно ускорить обработку данных и предлагает широкий спектр инструментов для работы с потоками данных, машинным обучением и графовыми вычислениями. Мы также погрузимся в мир Apache Kafka – платформы, которая революционизировала подход к потоковой передаче данных, предоставляя мощные инструменты для интеграции и обработки данных в реальном времени.
Эта книга предназначена для того, чтобы стать вашим проводником в мире больших данных. Независимо от того, являетесь ли вы новичком или опытным специалистом, вы найдете здесь ценные знания и практические примеры, которые помогут вам достичь новых высот в вашем деле. Я надеюсь, что она вдохновит вас на эксперименты и открытия в этой захватывающей области.
С уважением,
Джейд Картер
Глава 1. Введение в Технологии Больших Данных
– Определение и значение больших данных
– История и эволюция технологий больших данных
– Обзор экосистемы Hadoop и сопутствующих технологий
Определение и значение больших данных:
Большие данные (Big Data) – это наборы данных, которые настолько велики или сложны, что традиционные методы обработки данных не справляются с ними. Эти данные включают структурированную, полуструктурированную и неструктурированную информацию, которую можно анализировать, чтобы выявлять тенденции, закономерности и другие полезные сведения.
Такие данные могут поступать из различных источников, включая социальные сети, интернет-устройства, транзакционные системы, сенсоры и многое другое. Важные характеристики больших данных обычно описываются через концепцию "5 V»:
Volume (Объём): Огромное количество данных, измеряемое в петабайтах и эксабайтах.
Velocity (Скорость): Высокая скорость создания и обработки данных.
Variety (Разнообразие): Разнообразие типов данных (структурированные, неструктурированные, полуструктурированные).
Veracity (Достоверность): Качество данных, включая их точность и достоверность.Value (Ценность): Возможность извлечения полезной информации и создания ценности для бизнеса или научных исследований.
Значение больших данных заключается в их способности радикально трансформировать бизнесы и организации, обеспечивая более глубокое понимание различных аспектов их деятельности. Прежде всего, большие данные позволяют компаниям анализировать огромные массивы информации в реальном времени или почти в реальном времени, что существенно ускоряет процесс принятия решений. Это особенно важно в условиях высокой конкуренции, где скорость реакции на изменения рынка или поведения клиентов может стать ключевым преимуществом. Например, в ритейле анализ данных о покупках и предпочтениях клиентов позволяет прогнозировать спрос, оптимизировать запасы и даже персонализировать предложения, что в конечном итоге увеличивает продажи и снижает затраты.
Кроме того, анализ больших данных позволяет глубже понимать поведение клиентов. Компании могут отслеживать не только прямые взаимодействия с клиентами, такие как покупки или обращения в службу поддержки, но и косвенные данные, например, активность в социальных сетях, отзывы и комментарии. Это дает возможность формировать более точные профили клиентов и создавать персонализированные маркетинговые стратегии. Например, благодаря большим данным можно определить, какие продукты или услуги вызывают наибольший интерес у определённых сегментов аудитории, и адаптировать маркетинговые кампании под их нужды и предпочтения.
Кроме маркетинга и продаж, большие данные имеют важное значение и для оптимизации внутренних операций компаний. С их помощью можно анализировать процессы производства, логистики, финансового управления и других аспектов деятельности. Это позволяет выявлять узкие места, предсказывать и предотвращать сбои, повышать эффективность использования ресурсов и снижать операционные расходы. В таких отраслях, как производство или энергетика, анализ данных может привести к значительным улучшениям, включая оптимизацию процессов техобслуживания оборудования, снижение потребления энергии и минимизацию потерь.
В конечном итоге, большие данные не только способствуют повышению эффективности и снижению затрат, но и создают новые возможности для бизнеса. Они позволяют разрабатывать инновационные продукты и услуги, выходить на новые рынки, создавать новые бизнес-модели. Например, компании могут использовать анализ данных для разработки новых функций продуктов на основе анализа пользовательского опыта или для создания новых сервисов на основе анализа потоков данных в реальном времени.
Значение больших данных заключается не только в их объёме, но и в их способности приносить реальные преимущества бизнесу, трансформируя его подходы к работе с информацией и взаимодействию с клиентами, что в конечном итоге ведет к улучшению конкурентоспособности и устойчивому развитию.
История и эволюция технологий больших данных
Технологии больших данных имеют свою историю, которая берет начало с начала развития информационных технологий:
– 1970-е годы
В 1970-е годы произошел значительный прорыв в области хранения и управления данными с появлением реляционных баз данных (RDBMS). До этого времени данные хранились в основном в виде иерархических или сетевых моделей, которые были сложными и малоподходящими для масштабируемого хранения и обработки данных. Ключевой вехой этого периода стало введение концепции реляционных баз данных, предложенной Эдгаром Коддом, исследователем из компании IBM.
Реляционные базы данных основывались на простой и элегантной идее: данные организовываются в таблицы (реляции), где каждая строка представляет собой отдельную запись (запись), а каждая колонка – отдельное поле данных. Эта структура обеспечивала высокую гибкость и простоту управления данными. Кроме того, реляционная модель позволяла легко выполнять сложные запросы с использованием SQL (Structured Query Language) – стандартизированного языка запросов, разработанного для работы с реляционными базами данных. SQL стал одним из основных инструментов, позволившим пользователям манипулировать данными, выполнять поиск, сортировку, фильтрацию и объединение данных из разных таблиц.
Реляционные базы данных внесли фундаментальные изменения в способ организации и обработки данных. Они предложили средства для обеспечения целостности данных, таких как ограничения первичного и внешнего ключей, что позволило избежать дублирования данных и ошибок. Эти технологии также улучшили процессы транзакционной обработки, обеспечивая надёжность выполнения операций, что было критически важно для финансовых и бизнес-приложений.
IBM, Oracle и другие компании активно внедряли реляционные базы данных, что способствовало их широкому распространению в корпоративных средах. Появление реляционных баз данных и SQL стало основой для построения информационных систем и приложений, которые оставались в центре управления данными на протяжении десятилетий. Эти технологии заложили фундамент для современных систем управления базами данных (СУБД), и до сих пор реляционные базы данных продолжают играть ключевую роль в бизнесе и IT.
1970-е годы можно назвать эпохой формирования основ современных технологий работы с данными. Появление реляционных баз данных и SQL кардинально изменило подход к хранению и управлению информацией, сделав эти процессы более эффективными и доступными. Это заложило основы для последующих инноваций в области данных, которые мы наблюдаем и по сей день.
– 1980-е и 1990-е годы
В 1980-е и 1990-е годы мир начал стремительно меняться под воздействием революционных изменений в цифровых технологиях и интернета. Эти два десятилетия стали переломными моментами для обработки и управления данными, что привело к значительному росту объёмов данных и появлению новых подходов к их обработке.
В 1980-е годы произошел массовый переход от аналоговых систем к цифровым. Этот процесс охватил многие области: от офисных приложений до промышленных систем управления. Компьютеры стали дешевле и мощнее, что позволило большему числу организаций и частных лиц использовать их в своей работе. Одним из важных новшеств стало появление персональных компьютеров, которые дали возможность обрабатывать данные на рабочем месте, не прибегая к централизованным мощностям. В этот период начала активно развиваться база данных клиентов, финансовая аналитика и другие приложения, требующие значительных вычислительных мощностей.
Однако ключевым фактором, который изменил правила игры, стало развитие интернета в 1990-е годы. Сначала интернет служил в основном для обмена научной информацией и использования электронной почты, но в течение 1990-х он стал коммерческим и массовым, охватывая миллионы пользователей по всему миру. Внедрение World Wide Web (WWW) открыло новые горизонты для распространения и создания контента. Сайты, форумы, блоги и электронная коммерция стали генерировать огромные объёмы данных, что в итоге привело к проблемам с их хранением и обработкой.
Одним из значительных вызовов, с которыми столкнулись компании в этот период, стало управление растущими объёмами данных, поступающих из множества различных источников. Традиционные реляционные базы данных, хоть и продолжали играть важную роль, начали испытывать трудности с масштабируемостью и производительностью при работе с такими объёмами данных. Это привело к активному поиску новых подходов и технологий для обработки больших массивов данных. Например, начали развиваться технологии распределённых систем и кластерных вычислений, которые позволяли разбивать большие задачи на множество мелких и обрабатывать их параллельно на множестве машин.
Также в 1990-е годы появились новые методы и модели работы с данными, такие как онлайновая аналитическая обработка данных (OLAP) и хранилища данных (Data Warehouses). Эти технологии позволяли компаниям более эффективно извлекать и анализировать данные из различных источников, что в свою очередь способствовало развитию бизнес-аналитики и системы поддержки принятия решений. В этот период также начались эксперименты с нереляционными базами данных и новыми языками запросов, которые предоставляли более гибкие и быстрые способы работы с неструктурированными данными.
1980-е и 1990-е годы стали временем колоссальных изменений в мире данных. Развитие интернета и цифровых технологий привело к экспоненциальному росту объёмов данных, которые стали основой для нового этапа в обработке и анализе информации. Этот период заложил фундамент для появления технологий больших данных, которые вскоре стали необходимостью в условиях продолжительного роста объёмов и сложности данных в XXI веке.
– Начало 2000-х
В начале 2000-х годов мир оказался на пороге новой эры в обработке и управлении данными. Этот период ознаменовался стремительным ростом объёмов данных, что стало возможным благодаря взрывному развитию интернета, социальных сетей, мобильных технологий и устройств, генерирующих данные (например, сенсоры и интернет вещей). В результате традиционные базы данных и аналитические инструменты оказались неспособны справляться с новым уровнем сложности и масштабов данных. Это привело к появлению концепции «больших данных» (Big Data) и необходимости разработки новых методов и технологий для их обработки.
Основная проблема, с которой столкнулись компании и исследователи в начале 2000-х годов, заключалась в том, что объёмы данных начали расти с такой скоростью, что существующие системы управления базами данных (СУБД), построенные на реляционной модели, просто не могли их обработать в разумные сроки. Например, такие интернет-гиганты, как Google, Yahoo и Amazon, начали генерировать и собирать терабайты данных каждый день, что стало серьёзным вызовом для их инфраструктуры. Потребовались новые подходы к хранению и обработке данных, которые могли бы обеспечить не только масштабируемость, но и высокую производительность при обработке больших объёмов информации.
В ответ на эти вызовы начались исследования в области распределённых систем обработки данных. Одним из ключевых моментов стало появление модели MapReduce, предложенной Google в 2004 году. Эта модель позволяла разбивать задачи обработки данных на множество небольших подзадач, которые могли параллельно выполняться на множестве серверов, а затем объединять результаты. Это был революционный подход, который заложил основу для многих современных технологий больших данных. MapReduce позволил решать задачи, связанные с обработкой терабайтов и даже петабайтов данных, что было невозможно с использованием традиционных методов.
Параллельно с развитием распределённых вычислений возникла потребность в надёжных и масштабируемых системах хранения данных, которые могли бы работать в распределённой среде. В ответ на это была разработана Google File System (GFS) – распределённая файловая система, обеспечивающая хранение данных на множестве серверов с возможностью обработки ошибок и отказоустойчивости. Эта технология стала основой для создания HDFS (Hadoop Distributed File System), которая в последующие годы стала важной частью экосистемы Hadoop.
Именно в этот период были заложены основы экосистемы Hadoop, которая стала одной из первых платформ для работы с большими данными. Hadoop, первоначально разработанный Дугом Каттингом и Майком Кафкареллом как проект с открытым исходным кодом, был вдохновлён публикациями Google о GFS и MapReduce. Hadoop предоставил разработчикам и компаниям доступ к инструментам, которые позволяли масштабировать обработку данных и работать с огромными объёмами информации, используя кластеры обычных серверов.
Концепция «больших данных» в начале 2000-х годов начала приобретать форму, описываемую через три ключевых аспекта – объём, скорость и разнообразие (Volume, Velocity, Variety). Объём данных продолжал расти с невероятной скоростью, что требовало новых решений по хранению и обработке. Скорость генерации данных также увеличивалась, особенно с развитием потоковых данных и реального времени, что требовало мгновенного анализа и реакции. Разнообразие данных, включавшее как структурированные, так и неструктурированные данные (например, текстовые данные, изображения, видео), стало ещё одной важной характеристикой, с которой традиционные системы не могли справиться.
Начало 2000-х годов стало переломным моментом в истории технологий обработки данных. Появление концепции «больших данных» и развитие распределённых систем, таких как Hadoop, открыло новые возможности для анализа и использования данных в масштабах, которые ранее были немыслимы. Эти технологии заложили основу для современной аналитики данных, искусственного интеллекта и машинного обучения, которые сейчас активно используются во многих отраслях и определяют развитие глобальной цифровой экономики.
– Середина 2000-х
В середине 2000-х годов произошёл качественный скачок в развитии технологий для работы с большими данными благодаря созданию и стремительному развитию экосистемы Hadoop. Эта экосистема стала фундаментом для хранения и обработки огромных объёмов данных, и её влияние на IT-индустрию сложно переоценить.
Основой для Hadoop послужила модель MapReduce, разработанная Google. Эта модель, опубликованная в 2004 году, предложила революционный способ обработки данных в распределённых системах. MapReduce позволяла разбивать большие задачи на множество подзадач, которые могли обрабатываться параллельно на различных серверах, а затем объединять результаты. Этот подход значительно улучшил масштабируемость и производительность обработки данных, особенно в условиях растущих объёмов информации, с которыми начали сталкиваться крупные интернет-компании.
На базе идей MapReduce и вдохновлённый публикациями Google, Дуг Каттинг и Майк Кафкарелла начали работу над проектом с открытым исходным кодом, который в итоге стал известен как Hadoop. Первоначально Hadoop был создан как часть проекта Nutch – поисковой системы, также разрабатываемой Дугом Каттингом, – однако вскоре Hadoop выделился в отдельный проект, полностью сосредоточенный на хранении и обработке больших данных. Одним из первых пользователей и активных участников разработки Hadoop стала компания Yahoo, которая в 2006 году внедрила его для своих задач, связанных с обработкой огромных объёмов веб-данных.
Одним из ключевых компонентов Hadoop стала распределённая файловая система HDFS (Hadoop Distributed File System). HDFS была разработана для того, чтобы решать проблемы хранения и управления данными в распределённых системах. Основная идея HDFS заключалась в том, чтобы хранить данные не на одном сервере, а распределять их по множеству серверов в кластере, что обеспечивало высокую надёжность и отказоустойчивость. В случае выхода из строя одного из серверов данные не терялись, так как они были дублированы на других узлах кластера. HDFS также обеспечивала эффективное распределение данных между узлами и позволяла параллельно обрабатывать их с помощью MapReduce.
Hadoop быстро стал популярным благодаря своей способности работать с огромными объёмами данных и использовать недорогие, широко распространённые серверы для создания мощных кластеров. Это сделало технологию доступной не только для крупных корпораций, но и для малого и среднего бизнеса, которым также нужно было справляться с растущими объёмами данных. Hadoop и HDFS оказались крайне эффективными для таких задач, как индексация веб-страниц, анализ логов, обработка данных с сенсоров и других сценариев, где данные поступают в огромных объёмах и требуют сложной обработки.
Экосистема Hadoop продолжала развиваться, обрастая новыми инструментами и компонентами. Вокруг Hadoop начали появляться такие проекты, как Pig, Hive, HBase, и другие, которые расширяли возможности работы с данными. Pig и Hive предложили более высокоуровневые средства для написания задач обработки данных, что упростило работу с Hadoop для разработчиков, не знакомых с моделью MapReduce на низком уровне. HBase, в свою очередь, предложил нереляционную базу данных, работающую поверх HDFS, что позволило эффективно хранить и обрабатывать данные, не структурированные в виде таблиц.
Середина 2000-х годов стала временем формирования мощной и гибкой экосистемы Hadoop, которая не только смогла справляться с вызовами, связанными с большими данными, но и сделала это доступным для широкого круга пользователей и компаний. Эта экосистема стала основой для многих современных приложений и решений в области больших данных, и её принципы продолжают определять развитие технологий в этой области.
– С 2010-х годов и до настоящего времени
С начала 2010-х годов технологии обработки и анализа больших данных претерпели значительную эволюцию. Эти изменения были вызваны стремительным ростом объёмов данных, усложнением их структур и увеличением потребностей бизнеса в реальном времени. В ответ на эти вызовы начали развиваться новые инструменты и платформы, которые расширили возможности работы с большими данными и сделали этот процесс более гибким, быстрым и доступным.
Одним из наиболее значимых достижений этого периода стало появление Apache Spark – высокопроизводительной платформы для распределённой обработки данных. Spark, разработанный в 2009 году в Калифорнийском университете в Беркли и позже переданный в Apache Software Foundation, предложил новую парадигму обработки данных, которая отличалась от традиционного подхода Hadoop MapReduce. Основное преимущество Spark заключалось в его возможности хранить данные в оперативной памяти, что значительно ускоряло обработку, особенно при выполнении повторных операций над одними и теми же данными. Кроме того, Spark поддерживал различные типы задач, включая потоковую обработку данных (Spark Streaming), работу с графами (GraphX), и машинное обучение (MLlib). Благодаря этим возможностям Spark быстро стал популярным инструментом для обработки данных в реальном времени и сложных аналитических задач.
Параллельно с развитием Apache Spark, начался активный рост технологий NoSQL баз данных. Традиционные реляционные базы данных (RDBMS) оказались недостаточно гибкими для работы с разнообразными и неструктурированными данными, которые стали появляться в огромных объёмах с развитием интернета и мобильных устройств. NoSQL базы данных, такие как Cassandra, MongoDB, Couchbase и другие, предложили новые модели хранения данных, ориентированные на горизонтальную масштабируемость, высокую доступность и поддержку разнообразных структур данных. Например, Cassandra, изначально разработанная в Facebook, позволяла обрабатывать огромные объёмы данных в распределённых системах с высокой доступностью, что делало её идеальным выбором для приложений, работающих в реальном времени. MongoDB, с другой стороны, предложила документно-ориентированную модель, которая позволяла гибко хранить и управлять данными, не требующими фиксированной схемы.
Ещё одной важной вехой в развитии технологий больших данных стало появление и развитие инструментов для потоковой обработки данных, таких как Apache Kafka и Apache Flink. Apache Kafka, разработанная в LinkedIn и переданная в Apache Software Foundation в 2011 году, стала де-факто стандартом для передачи и обработки потоков данных в реальном времени. Kafka позволяла собирать, хранить и передавать большие объёмы данных с высокой пропускной способностью и низкой задержкой, что сделало её незаменимым инструментом для построения систем, требующих мгновенной обработки данных, таких как системы рекомендаций, мониторинг сетевого трафика, и многие другие. Apache Flink, появившийся чуть позже, предложил дополнительные возможности для обработки потоков данных, включая поддержку сложных событий и точную обработку состояния, что сделало его одним из самых мощных инструментов для анализа данных в реальном времени.
Одновременно с развитием технологий обработки данных происходило стремительное развитие облачных вычислений. Сервисы облачных платформ, таких как Amazon Web Services (AWS), Google Cloud Platform (GCP) и Microsoft Azure, значительно упростили процесс работы с большими данными, предоставляя масштабируемую инфраструктуру и разнообразные инструменты в качестве услуг по запросу. Эти облачные сервисы предложили интегрированные решения для хранения данных, такие как Amazon S3 или Google Cloud Storage, а также мощные аналитические инструменты, такие как Amazon Redshift или Google BigQuery. С помощью облачных платформ компании смогли быстро развертывать и масштабировать свои решения, не беспокоясь о поддержке собственной инфраструктуры. Это позволило не только снизить затраты, но и ускорить внедрение инноваций в области больших данных.
Кроме того, облачные платформы начали предлагать готовые сервисы для машинного обучения и искусственного интеллекта, что позволило компаниям интегрировать сложные аналитические функции в свои продукты и услуги без необходимости разработки собственных моделей с нуля. Эти облачные решения включали в себя инструменты для построения, обучения и развертывания моделей машинного обучения, такие как AWS SageMaker, Google AI Platform и Azure Machine Learning.
С 2010-х годов и до настоящего времени технологии и инструменты для работы с большими данными прошли значительный путь развития, предоставив мощные, гибкие и доступные решения для обработки, хранения и анализа данных. Эти инновации стали основой для современных подходов к управлению данными, позволяя организациям эффективно использовать большие данные для улучшения бизнеса, повышения производительности и внедрения новых технологий.
Обзор экосистемы Hadoop и сопутствующих технологий
Hadoop – это основа экосистемы больших данных, которая включает в себя множество компонентов и инструментов для обработки и анализа больших объемов данных.
Основные компоненты Hadoop:
– HDFS (Hadoop Distributed File System)
HDFS (Hadoop Distributed File System) является одной из ключевых технологий, лежащих в основе экосистемы Hadoop, и играет центральную роль в хранении и управлении большими объемами данных. Разработанная для работы в условиях распределенных вычислений, HDFS обеспечивает надёжное и масштабируемое хранение данных на множестве машин (или узлов), что позволяет эффективно обрабатывать петабайты и эксабайты информации.
Основной принцип работы HDFS заключается в том, что большие файлы разбиваются на более мелкие блоки данных, которые затем распределяются и хранятся на разных узлах кластера. По умолчанию размер одного блока в HDFS составляет 128 МБ, но этот параметр может быть изменён в зависимости от потребностей конкретной задачи. Каждому блоку назначается уникальный идентификатор, что позволяет системе отслеживать его местоположение и состояние.
Одной из самых важных характеристик HDFS является его отказоустойчивость. Для обеспечения надёжности и доступности данных, каждый блок автоматически дублируется (реплицируется) на нескольких узлах кластера. Например, если стандартное значение коэффициента репликации равно 3, это означает, что каждый блок будет храниться на трёх различных узлах. В случае отказа одного из узлов, HDFS автоматически перенаправит запросы на другие узлы, где хранятся копии блоков, что позволяет избежать потери данных и минимизировать время простоя системы. Этот механизм делает HDFS высоко надёжной системой для работы в условиях частых аппаратных сбоев, которые неизбежны при работе с большими распределёнными системами.
Ещё одной важной особенностью HDFS является его способность к масштабированию. Система изначально спроектирована так, чтобы добавление новых узлов к кластеру не требовало значительных изменений в конфигурации или архитектуре. Это позволяет легко увеличивать объём хранимых данных и мощность обработки, добавляя новые серверы по мере необходимости. Масштабируемость HDFS делает её идеальной для крупных организаций, которым необходимо хранить и анализировать растущие объёмы данных без значительных затрат на инфраструктуру.
Архитектура HDFS построена по принципу «мастер-слейв» (master-slave). Центральным элементом системы является NameNode – главный сервер, который управляет метаданными и отвечает за координацию всех операций с файловой системой. NameNode отслеживает, на каких узлах хранятся блоки данных, обрабатывает запросы на чтение и запись данных, а также управляет репликацией блоков для обеспечения отказоустойчивости. DataNode, в свою очередь, является «рабочей лошадкой» системы – это узлы, непосредственно хранящие блоки данных и выполняющие операции по их чтению и записи по указаниям NameNode. Такая архитектура позволяет эффективно распределять нагрузку между узлами и обеспечивает высокую производительность системы.
Однако важность NameNode в архитектуре HDFS также делает его «единой точкой отказа» (single point of failure). Потеря NameNode может привести к полной недоступности данных в кластере. Для решения этой проблемы были разработаны дополнительные механизмы защиты и восстановления, такие как резервное копирование метаданных, введение резервного NameNode (Standby NameNode) и распределение нагрузки между несколькими NameNode в крупных кластерах. Эти меры значительно повысили надёжность и доступность HDFS.
HDFS также поддерживает функции, необходимые для эффективной работы в условиях большого количества одновременно выполняемых задач и разнообразных типов данных. Например, система оптимизирована для последовательного доступа к данным (предполагается, что большинство операций будет представлять собой чтение или запись больших блоков данных). Такая оптимизация делает HDFS особенно эффективной для аналитических задач, таких как обработка больших журналов данных, индексация веб-страниц, и другие задачи, где требуется последовательное чтение и обработка значительных объёмов информации.
HDFS тесно интегрирован с другими компонентами Hadoop, такими как MapReduce и YARN, что делает его неотъемлемой частью всей экосистемы Hadoop. Он служит базой для различных инструментов и приложений, которые используют распределённые вычисления и большие данные, предоставляя надёжную и масштабируемую инфраструктуру для хранения и обработки информации. В конечном счёте, HDFS стал ключевым элементом, благодаря которому Hadoop получил широкое распространение в мире обработки больших данных и обеспечил революцию в этой области, позволив организациям эффективно работать с огромными объёмами информации. (Рис. 1)
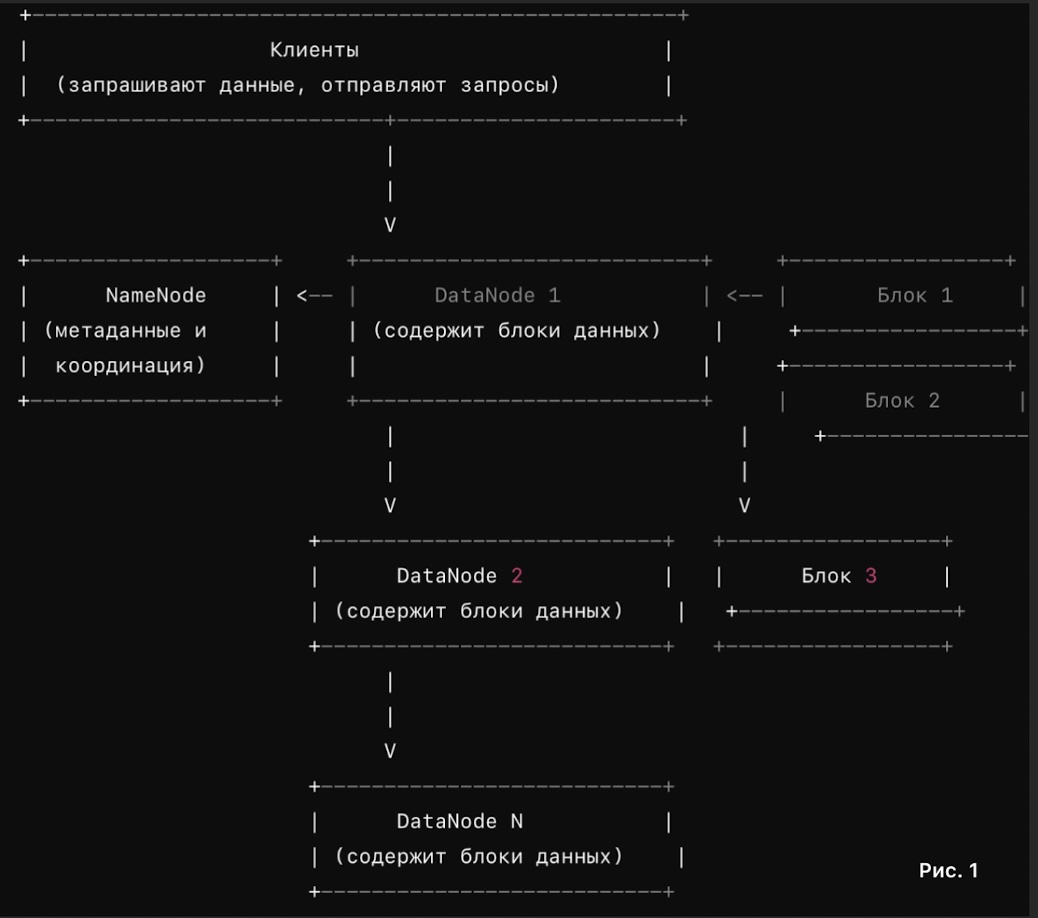
Общая схема HDFS
Имя узла (NameNode)
Расположение: В центре схемы.
Функции: Управляет метаданными (структурой каталогов, размещением блоков и информацией о репликации). Служит центральным координационным элементом.
Данные узлы (DataNodes)
Расположение: Окружает NameNode. Обычно несколько DataNodes.
Функции: Хранят фактические данные в виде блоков и обеспечивают операции чтения и записи.
Блоки данных
Расположение: На DataNodes.
Функции: Файлы делятся на блоки, которые хранятся на разных DataNodes. Каждый блок имеет несколько реплик.
Клиенты
Расположение: Снаружи от NameNode и DataNodes.
Функции: Запрашивают чтение или запись данных в HDFS.
Соединения и поток данных
Связь между клиентами и NameNode
Описание: Клиенты отправляют запросы на NameNode для получения информации о размещении блоков и для доступа к данным.
Связь между NameNode и DataNodes
Описание: NameNode управляет метаданными и информирует DataNodes о том, какие блоки данных где хранятся и каковы их реплики.




