



Тимур Машнин
Введение в технологию Блокчейн
Введение в криптографию и криптовалюты
Начнем мы свое обсуждение с криптографических хеш-функций. Мы поговорим о том, что они собой представляют, и каковы их свойства. А потом мы обсудим их приложения.
Итак, криптографическая хэш-функция является математической функцией. И она обладает рядом свойств.

Прежде всего, хеш-функция может принимать любую строку любого размера как входной параметр. И хеш-функция производит вывод строки фиксированного размера, мы будем использовать 256 бит, потому что это делает биткойн.
И хеш-функция должна быть эффективно вычисляемой, обрабатывая заданную строку за разумный промежуток времени.
Также хэш-функция должна быть криптографически безопасна.
В частности, функция не должна иметь коллизий или конфликтов, она должна иметь свойство скрытия, и она должна быть головоломкой.
Первое свойство, которое нам нужно иметь для криптографической хеш-функции это то, что она не содержит конфликтов.
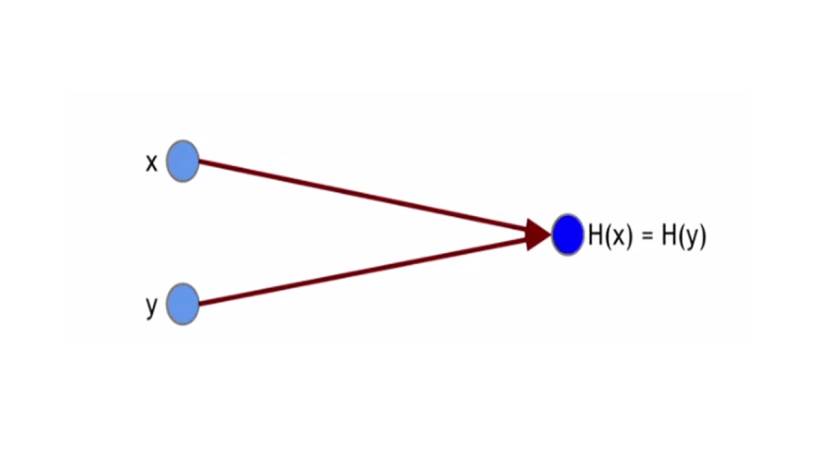
И это означает, что нельзя найти две разные строки с одинаковой хэш-функцией.
Теоретически коллизии существуют, так как на вход вы берете строку любой длины, а на выходе получаете строку 256 бит.
Вопрос в том, могут ли эти коллизии быть найденными обычными людьми, использующими обычные компьютеры?
С точки зрения вероятности, если взять 2 в 130 степени случайно выбранных входных строк, то с вероятностью 99.8 %, по крайней мере, две из них будут конфликтовать, независимо от используемой хэш функции.
Но, конечно, проблема в том, что вы должны вычислить хэш функцию 2 в 130 степени раз.
И это, конечно, астрономическое число.
Не существует хеш функции, для которой было бы доказано, что она свободна от конфликтов.
Просто эти конфликты трудно найти, и мы принимаем то, что мы используем хэш функцию, свободную от конфликтов.
Если мы можем предположить, что у нас есть хеш-функция, свободная от коллизий, тогда мы можем использовать результаты этой хэш-функции как дайджест сообщений.
И я имею в виду следующее.
Если мы знаем, что x и y имеют одинаковый хеш, тогда можно с уверенностью предположить, что x и y одинаковы. И это позволяет нам использовать хэши как своего рода дайджест сообщений.
Предположим, например, что у нас есть большой файл.
И мы хотели бы уметь распознавать, будет ли другой файл таким же, как этот файл.
Один из способов сделать это, это сохранить весь большой файл. И затем, когда мы получим другой файл, просто сравнить их.
Но поскольку у нас есть хэш функция и хэши файлов, которые, как мы считаем, свободны от конфликтов, более эффективно просто запомнить хэш исходного файла.
Затем, если кто-то показывает нам новый файл и утверждает, что это то же самое, мы можем вычислить хэш этого нового файла и сравнить хеши.
Если хеши одинаковы, мы делаем вывод, что файлы одинаковые.
И это дает нам очень эффективный способ запомнить то, что мы видели раньше, так как хэш невелик, это всего лишь 256 бит, в то время как исходный файл может быть очень большим.
Второе свойство, которое мы хотим от хэш-функции, состоит в том, что она является скрывающей.
Если у нас есть результат хэш-функции, тогда нет никакого способа определить, что из себя представляет вход хэш функции.
Это работает, когда вход хэш функции представляет собой огромный набор различных вариантов, так что нельзя простым перебором, вычисляя хэши, найти соответствие хэша и определенного входа.
Если же у нас набор входных значений небольшой, мы можем решить эту проблему с помощью соединения нашего входного значения со значением, которое было выбрано из очень большого набора значений.
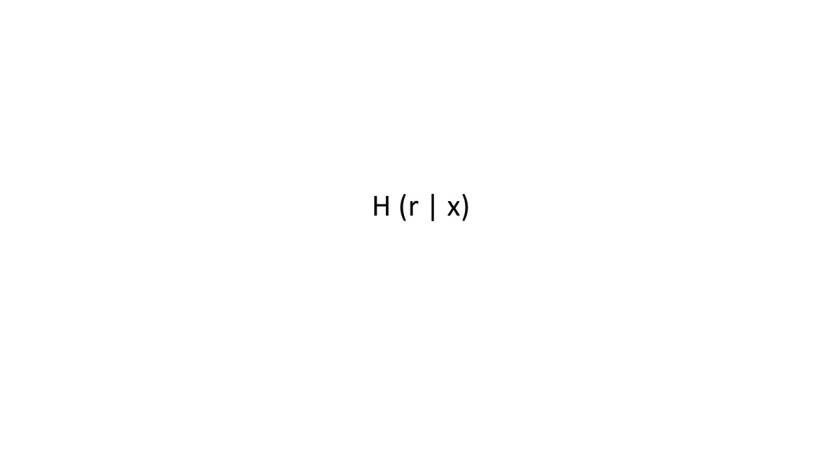
Таким образом, хэш функция H (r | x) означает взять все биты r и поместить после них все биты x.
Если r – случайное значение, выбранное из широкого распределения, то, учитывая H (r | x), невозможно найти x.
Таким образом хэш r соединенного с x, будет скрывать x.
Теперь давайте посмотрим на применение этого скрывающего свойства.
Предположим, что мы берем число, заворачиваем его в конверт, и помещаем его на стол, где каждый может увидеть конверт. Но пока вы не открыли конверт, это число является секретом.
Позже вы можете открыть конверт и выдать значение.
Мы хотим сделать это в цифровом смысле. Например, вы можете передать сообщение.
И эта передача выдаст два значения, com и key.
Подумайте о com как о конверте, который вы собираетесь положить на стол, и ключе как о секретном ключе для разблокировки конверта.
Затем вы позволяете кому-то проверять, учитывая com, key и сообщение, что этот конверт, ключ и сообщение действительно идут вместе.
И эта проверка вернет истину или ложь.
Мы помещаем сообщение в конверт и передаем сообщение.
И эта передача возвращает конверт и ключ, а затем мы публикуем конверт.
Позже, чтобы открыть конверт, мы должны опубликовать ключ.
И тогда кто-то может использовать этот конверт, ключ и сообщение, чтобы проверить валидность открытия конверта.
Таким образом невозможно будет подменить сообщение в конверте.

Чтобы реализовать эту схему, мы генерируем случайное значение 256 бит и назовем его ключом.
И тогда мы вернем хэш ключа, соединенного с сообщением.
Затем, кто-то может проверить целостность сообщения, вычислив хэш ключа и сообщения и сравнив это значение с переданным значением com.
сom – это хэш ключа, соединенного с msg.
И если есть этот хэш, по нему невозможно узнать само сообщение.
Это то самое свойство скрытия, о котором мы говорили раньше.
Ключ был выбран случайным 256-битным значением.

И поэтому свойство сокрытия означает, что, если мы возьмем сообщение, и поставим перед ним что-то, что было выбрано из очень большого распределения, как в данном случае случайное 256-битное значение, тогда невозможно найти сообщение, как исходя из самого хэша, так и простым перебором возможных сообщений.
Одновременно мы получаем и отсутствие конфликтов, используя такую схему.
Невозможно будет найти два разных сообщения с одинаковым таким хэшем.
Используя все эти свойства хэша, мы можем сделать приложение – поиск пазла, математическую задачу, которая требует больших вычислений.
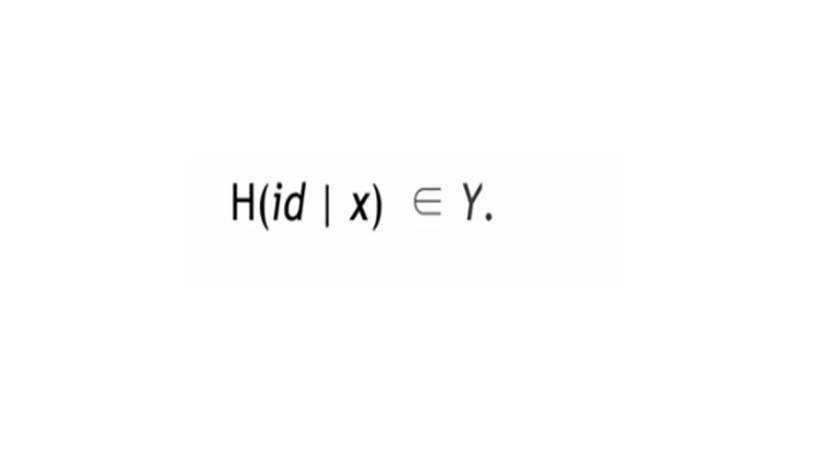
Используя id из большого распределения, нужно найти x, чтобы хэш id и x попадал в заранее определенное распределение y.
Если мы хотим создать головоломку, которую трудно решить, мы можем сделать это таким образом, генерируя идентификаторы головоломок в случайном порядке.
И мы будем использовать это позже, когда мы поговорим о майнинге биткойнов.
Это своего рода вычислительная загадка, которую мы будем использовать.
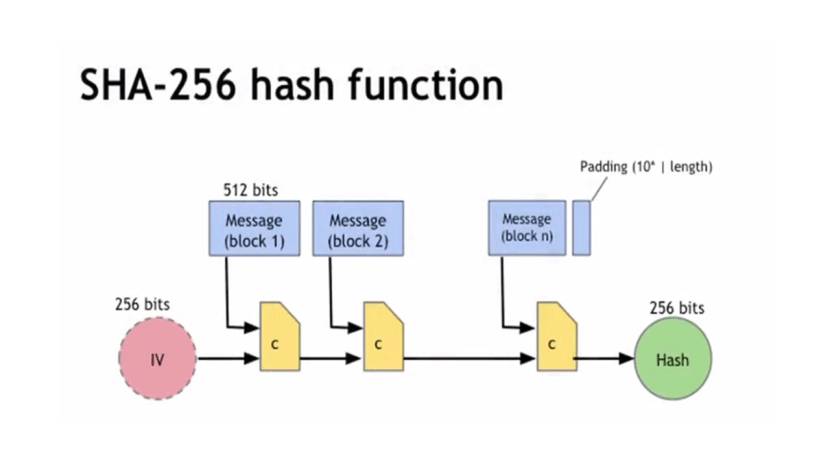
Существует множество хэш функций, но функция, которую использует биткойн, это функция, которая называется SHA-256, и она работает следующим образом.
Она принимает сообщение, которое вы хешируете, и она разбивает его на блоки размером 512 бит.
Сообщение не обязательно кратно размеру блока, поэтому мы должны добавить в конце дополнение. И это дополнение будет состоять из, в конце дополнения, поля длиной 64 бит, которое является длиной сообщения в битах.
И затем до этого находится один бит, за которым следует некоторое количество нулевых бит.
И вы выбираете число нулевых бит, чтобы выйти точно в конец блока.
После того как вы разбили сообщение на блоки, вы начинаете вычисление.
Вы начинаете с 256-битного начального значения и берете первый блок сообщения.
Затем вы берете эти 768 полных битов, и обрабатываете специальной функцией сжатия, которая на выходе дает 256 бит.
Вы берете полученные 256 бит и следующие 512 бит сообщения, снова пропускаете через функцию сжатия и так далее, пока не обработаете все блоки сообщения.
Таким образом вы получите хэш, как 256-битное значение.
И нетрудно показать, что если эта функция сжатия, C, является свободной от коллизий, то вся эта хэш-функция также будет свободна от коллизий.
Хэш указатели и структуры данных
Далее мы поговорим о хэш указателях и их применении.
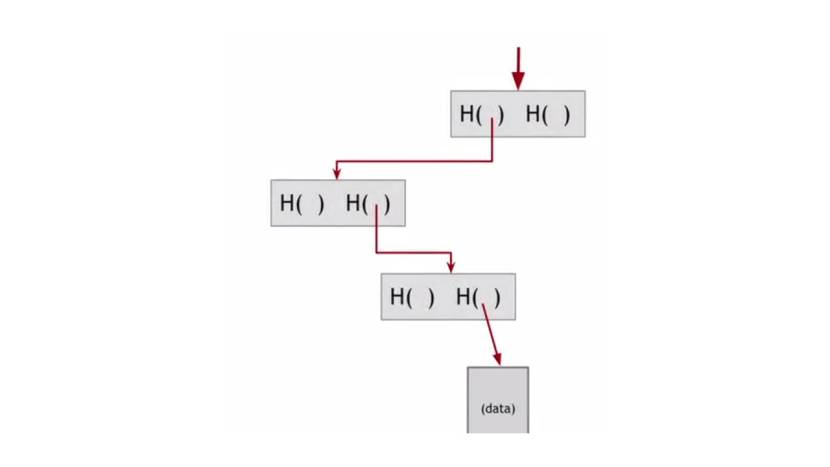
Хэш указатель – это вид структуры данных, которая указывает где хранится некоторая информация.
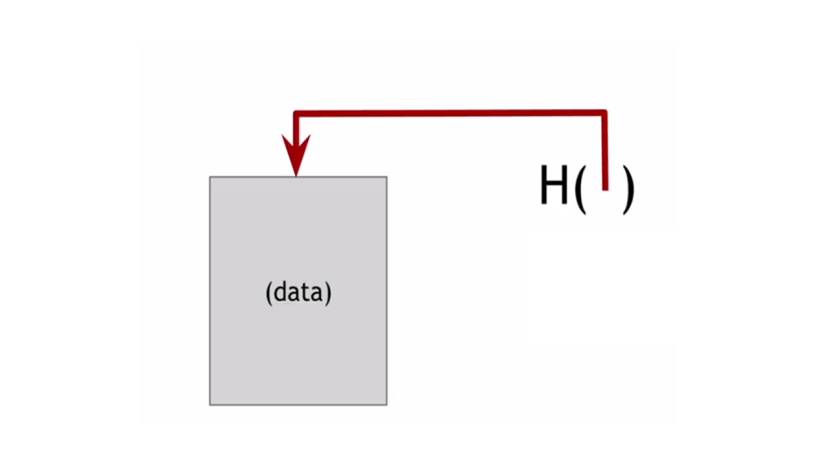
И в которой вместе с указателем хранится криптографический хэш самой информации.
Поэтому, если обычный указатель дает способ получения информации, хеш-указатель позволяет не только получить информацию, но и также проверить, что эта информация не изменилась.
И мы можем использовать хэш указатели для создания всех видов структур данных.
Здесь ключевая идея, использовать любую структуру данных, связанные списки или двоичное дерево поиска или что-то вроде этого, и реализовать это с помощью хеш-указателей.
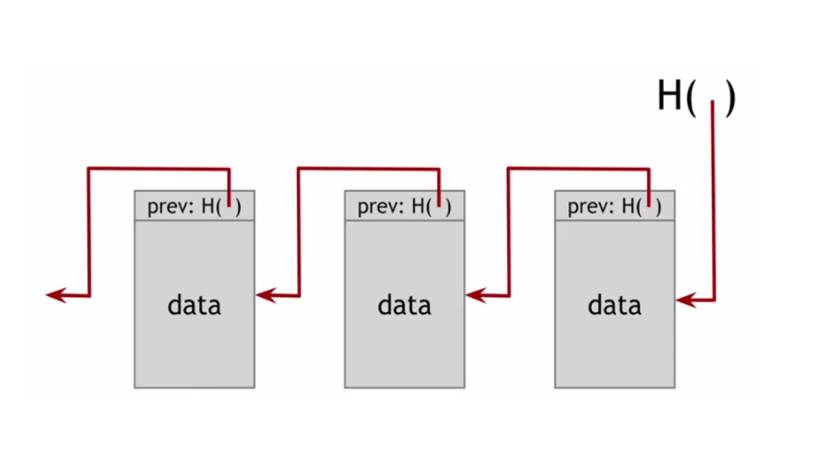
Например, здесь есть связанный список, который мы построили с помощью хэш-указателей.
И это структура данных, которую мы собираемся назвать цепочкой блоков.
Так что, по сравнению с обычным связанным списком, где у вас есть серия блоков, и каждый блок имеет данные, а также указатель на предыдущий блок в списке, здесь указатель на предыдущий блок заменяется на хэш-указатель, который хранит указатель на предыдущий блок и хэш всего содержимого блока.
Эта структура не только позволяет хранить данные, но и защищать их.
Теперь, что произойдет, если кто-то изменит данные в блоке.
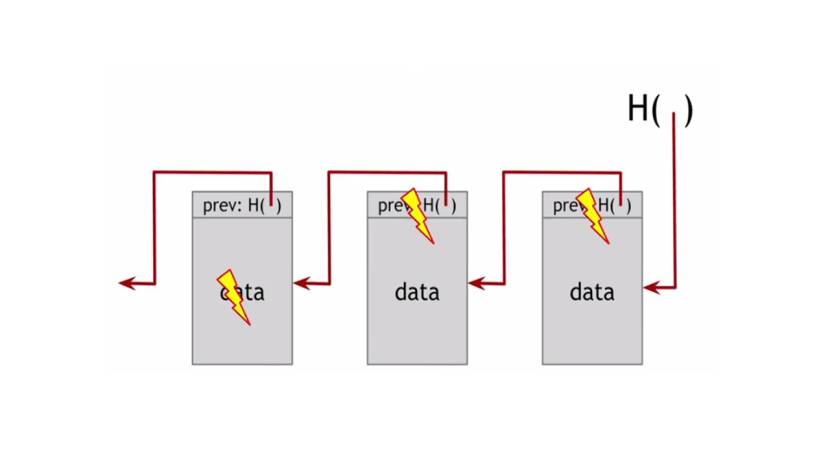
Мы это легко обнаружим, сравнив хэш указатель и данные блока.
Если же кто-то изменит и хэш-указатель предыдущего блока, тогда возникнет несогласованность с хэш-указателем следующего блока, так как хэш-указатель хранит хэш не только самих данных, но содержимого всего блока.
Поэтому злоумышленнику придется изменить хэш-указатели всей цепочки до конца.
Таким образом, один хэш-указатель защищает весь список от этого блока и до конца.
Начальный блок такого списка называется блоком генезиса.
Теперь, еще одна полезная структура данных, которую мы можем построить с помощью хеш-указателей, является двоичным деревом.
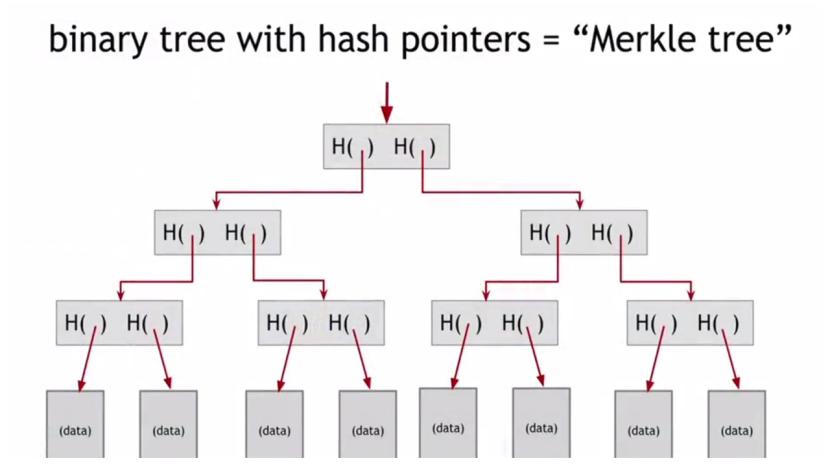
Идея в том, что у нас есть куча блоков данных, которые показаны внизу.
И используя пары блоков, мы строим структуры данных с двумя хеш-указателями, по одному на каждый из этих блоков.
Затем мы переходим на другой уровень, и здесь этот блок будет содержать хэш-указатель этих двух детей. И так далее, вплоть до корня дерева, единственный хэш которого мы и запоминаем.
И мы можем быть уверены, что данные не будут подделаны.
Потому что злоумышленнику придется изменять хэши на всех уровнях, пока он не доберется до вершины дерева, но здесь он не сможет изменить хэш, так как мы его запомнили.
Таким образом, мы защищаем всю структуру данных, просто запомнив один хэш.
Теперь еще одна приятная особенность деревьев Merkle заключается в том, что в отличие от ранее рассмотренной цепочки блоков, если кто-то хочет доказать нам, что конкретный блок данных является членом этого дерева Merkle, все, что им нужно, это показать эти данные.
Мы вычисляем хэш этих данных и поднимается вверх до корня дерева, так как мы помним только корень дерева, проверяя соответствие хэш-указателям.
И это занимает около log n элементов.
Поэтому при очень большом числе блоков данных в дереве Merkle мы можем проверить членство данных за относительно короткое время.
Таким образом, деревья Меркле имеют преимущества в том, что даже если дерево содержит много элементов, нам просто нужно запомнить хеш корня дерева, который составляет всего 256 бит.
И мы можем проверить принадлежность к дереву за логарифмическое время.
Также есть вариант Merkle дерева – это сортированное дерево Merkle.
В этом дереве мы берем блоки данных внизу и сортируем их в некотором порядке.
Алфавитном, лексикографическом, числовом порядок или каком-либо другом порядке.
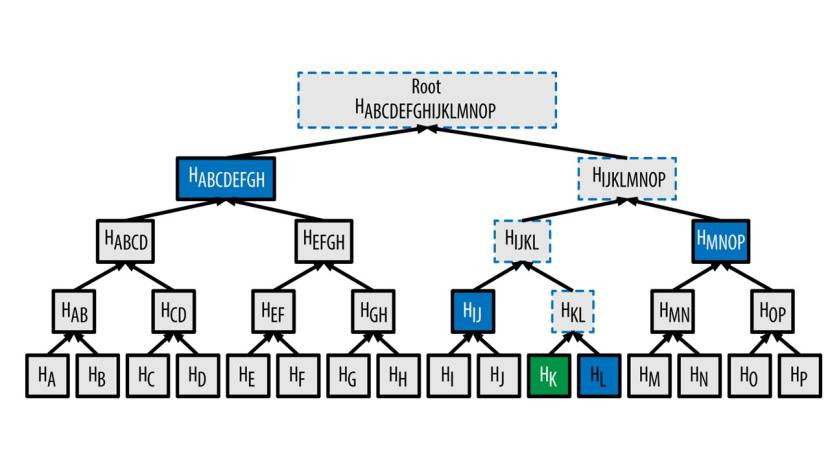
И как только мы отсортировали дерево Merkle, мы можем доказать, что конкретный блок не находится в дереве Merkle.
Мы можем сделать это, просто указав путь к элементу, который находится непосредственно перед местом, где этот элемент должен быть, и сразу после того, где он будет.
И тогда мы можем доказать, что оба эти элемента находятся в дереве Merkle последовательно.
И поэтому между ними нет места для элемента, который мы ищем.
Цифровые подписи
Далее мы поговорим о цифровых подписях.
Это второй криптографический примитив наряду с хеш-функциями, которые нам нужны в качестве строительных блоков для обсуждения криптовалюты.
Итак, цифровая подпись – это как подпись на бумаге только в цифровой форме.
И что это значит, что мы хотим от подписи? Это две вещи.
Во-первых, точно так же, как и для бумажной подписи, для цифровой подписи, только вы можете сделать свою подпись, но любой, кто видит вашу подпись может подтвердить, что она действительна.
И тогда вторая вещь, которую вы хотите, заключается в том, что подпись привязана к определенному документу.
Чтобы кто-то не мог взять вашу подпись с одного документа и приклеить ее на другой документ, потому что подпись – это не просто подпись.
Это означает ваше согласие или одобрение конкретного документа.
Теперь, как мы можем построить это в цифровой форме с использованием криптографии?

Вот API интерфейс для цифровых подписей.
Здесь есть три операции, которые мы должны делать.
Первое, нам нужно иметь возможность генерировать ключи, и поэтому у нас есть операции generateKeys, которая принимает размер ключа и создает два ключа, sk и pk.
Ключ sk будет секретным ключом подписи, это информация, которую вы держите в секрете и которую вы используете для создания своей подписи.
И ключ pk является общедоступным ключом проверки, который вы даете всем и который любой может использовать для проверки вашей подписи, когда они ее видят.
Вторая операция, это операция подписи.
Операция подписи берет секретный ключ подписи и сообщение, на котором вы хотите поставить свою подпись.
И она возвращает значение, которое является подписью и которое представляет собой лишь несколько бит, представляя вашу подпись.
И затем, третья операция – это проверка, которая берет то, что утверждается как правильная подпись, и подтверждает, что это действительно так или нет.
Эта операция принимает открытый ключ подписывающего лица, сообщение, к которому применена подпись, и принимает саму подпись.
И операция просто возвращает «да», если подпись действительна, или «нет», если она не действительна.
Таким образом, есть три операции, три алгоритма, которые составляют схему подписи.
Причем, первые два алгоритма могут быть рандомизированными алгоритмами.
Проверка всегда будет детерминированным алгоритмом.
Метод generateKeys должен быть рандомизированным, потому что он должен генерировать разные ключи для разных людей.
И подписи также должны отличаться для разных сообщений.
Подписи должны удовлетворять следующим двум требованиям.
Прежде всего, действительные подписи должны пройти проверку.
Если подпись действительна, т. е. если я подпишу сообщение с моим секретным ключом, и, если кто-то затем позже попытается проверить ее, используя мой открытый ключ и то же самое сообщение, подпись будет корректно проверяться.
Второе требование, это то, что невозможно подделать подписи.
То есть, злоумышленник, который знает ваш открытый ключ, ключ проверки, и может видеть подписи на некоторых других сообщениях, не сможет подделать вашу подпись на каком-либо другом сообщении.
На практике существует ограничение на размер сообщения, который вы можете подписать, поскольку реальные схемы работают с битовыми строками ограниченной длины.
Поэтому используется хэш сообщения, а не сам текст сообщения.
Таким образом, сообщение может быть действительно большим, но хэш будет только 256 бит.
И поскольку функции хэша не имеют коллизий, хэш сообщения безопасно использовать в качестве входного сигнала для схемы цифровой подписи, а не само сообщение.
И, кстати, забавный трюк, который мы будем использовать позже, заключается в том, что вы можете подписать хэш-указатель.
И если вы подписываете хэш-указатель, то подпись покрывает или защищает всю структуру, а не только сам указатель хеширования, но и все, на что он указывает.
Например, если вы подписываете хеш-указатель, который был в конце цепочки блоков, результатом будет то, что вы эффективно подписываете весь контент этой цепочки блоков.
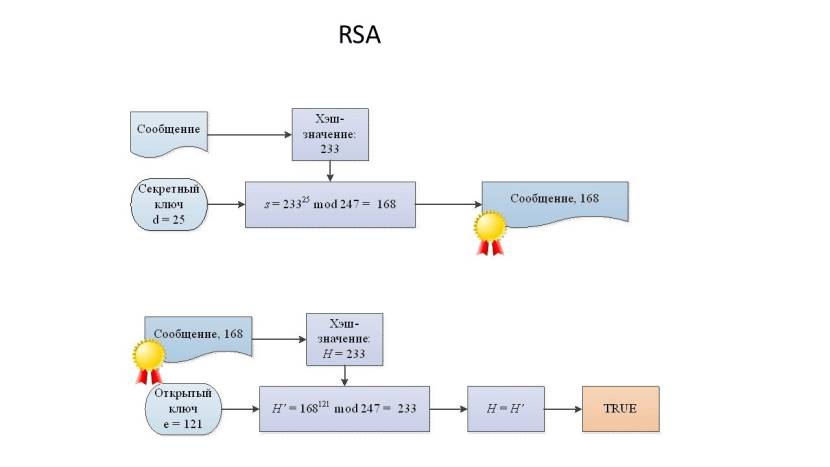
Это пример цифровой подписи с использованием алгоритма RSA.
Биткойн использует определенную схему цифровой подписи, которая называется ECDSA.
Это алгоритм эллиптической кривой Elliptic Curve Digital Signature Algorithm.
И это стандарт правительства США.
Мы не будем вдаваться во все детали того, как работает ECDSA.
Он полагается на сложную математику.
И поверьте мне, вы не хотите видеть все детали того, как это работает. Поэтому мы это пропустим.
Одна вещь, которую я хочу заметить, это то, что для ECDSA важна хорошая рандомизация. Хорошая случайность особенно важна для ECDSA.
Если вы используете плохую рандомизацию для генерации ключей или даже подписи, вы можете дать доступ к своему секретному ключу.
Это свойство ECDSA, что, если вы используете плохую случайность, создавая подпись с использованием совершенно хорошего ключа, это может дать доступ к приватному ключу.
Поэтому вы должны быть особенно внимательны к этому на практике. Это распространенная ошибка.
Теперь, если мы возьмем публичный ключ, общедоступный ключ проверки цифровой подписи, то мы можем приравнять его к идентичности.
То есть, идентифицировать с помощью него личность человека, или действие, или систему.
Поэтому, если вы видите подпись сообщения, верифицированную или подтвержденную с помощью публичного ключа, тогда вы можете думать об этом как о том, что публичный ключ представляет сообщение.
Вы можете думать о публичном ключе, как о своего рода участнике в системе, потому что за публичным ключом находится приватный ключ, который может принадлежать только одной личности.
Если мы собираемся рассматривать публичные ключи как личности, одним из последствий этого является то, что вы можете создать новую идентичность с помощью создания новой пары случайных ключей – секретный ключ и публичный ключ, используя операцию генерации ключей.
И публичный ключ будет публичным именем личности, хотя на практике используется хэш из публичного ключа, так как публичные ключи большие.
Вы контролируете личность, потому что только вы знаете секретный ключ, и, если вы сгенерировали ключи случайным образом, тогда никто не может знать, кто вы.
Вы можете создавать свежие идентичности, которые выглядят случайными.
Это подводит нас к идее децентрализованного управления идентификацией, где вместо того, чтобы иметь центральное место, куда вы должны пойти, чтобы зарегистрироваться как пользователь в системе, здесь вам не нужно получать имя пользователя.
Вам не нужно сообщать кому-то, что вы собираетесь использовать определенное имя.
Если вам нужна новая личность, просто создайте ее.
Любой может создать новую личность в любое время и может сделать их столько, сколько захочет.
Если вы захотите быть под пятью именами, без проблем, просто сделайте пять идентификаторов.
Если вы хотите быть анонимным, вы можете создать новую личность, использовать ее только на некоторое время, затем выбросить ее.
Все это возможно с помощью децентрализованного управления идентификацией.
И нет центральной точки контроля, так что вам не нужно иметь кого-то, кто отвечает за идентификацию.
Система работает полностью децентрализованным способом.
И таким способом Биткойн создает личности.
Эти личности называются адресами в терминологии Биткойна.
И поэтому, когда вы слышите термин «адрес» в разговоре о биткойне и криптовалютах, на самом деле это просто открытый ключ или хэш открытого ключа.
Это личность, которую кто-то создал в рамках децентрализованной схемы управления идентификацией.
Теперь возникает вопрос, когда вы говорите о децентрализованном управлении идентификацией и людях, создающих эти личности, насколько это конфиденциально?
И ответ в том, что это сложно.
С одной стороны, адреса, составленные таким образом, не связанны с вашей реальной личностью в реальном мире.
Вы выполняете рандомизированный алгоритм, он создает какой-то публичный ключ, который выглядит случайным.
И изначально ничего не существует, что может связать это с тем, кто вы есть на самом деле.
Вы можете сделать это конфиденциально.
Но плохая новость в том, что даже если вы хотите действовать конфиденциально, и, если этот адрес, эта личность делает ряд утверждений со временем, если этот адрес участвует в ряде действий, люди могут увидеть, кто сделал эту определенную последовательность действий, и они смогут связать этот адрес с конкретным человеком.
Поэтому вопрос конфиденциальности в криптовалюте является сложным вопросом.




