



Тимур Машнин
Машинное обучение и Искусственный Интеллект
Исходный код
Исходный код к примерам можно скачать с сайта GitHub.
Введение
ИИ резко меняет нашу жизнь и формирует наше будущее.
Всемирный экономический форум недавно опубликовал отчет, в котором говорится, что в период до 2022 года около 75 миллионов рабочих мест могут быть потеряны из-за машин.
Далее в отчете говорится, что 133 миллиона новых рабочих мест могут появиться из-за быстрого развития машин и ИИ.
Это означает 58 миллионов новых рабочих мест, которые будут созданы в ближайшие несколько лет.
ИИ состоит из 2-х слов Искусственный и интеллект.
Все, что не естественно и создано людьми, является искусственным.
Интеллект означает способность понимать, рассуждать, планировать и т. д.
Таким образом, мы можем сказать, что любой код, технология или алгоритм, которые позволяют машине имитировать, развивать или демонстрировать человеческое познание или поведение, являются ИИ.
И в наши дни много говорят об искусственном интеллекте.
Почему вырос интерес к ИИ?
Причина в том, что раньше у нас было очень мало данных.
Но в наши дни наблюдается огромный рост объема данных, которые генерируются каждую минуту и помогают нам делать более точные прогнозы.
Наряду с огромным объемом данных у нас также появились более совершенные алгоритмы, вычислительные мощности и хранилища данных, которые могут справиться с таким огромным объемом данных.
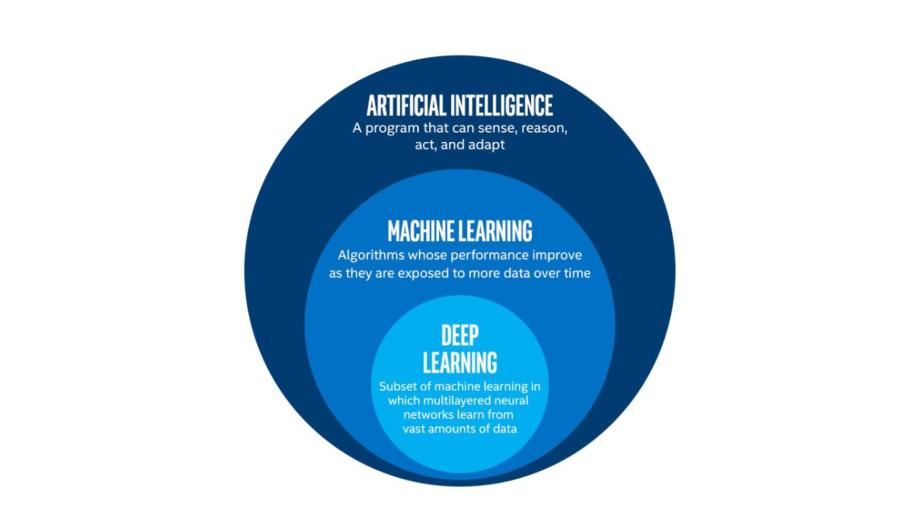
И искусственный интеллект – это очень широкое понятие, в которое входят машинное обучение и глубокое обучение.
В широком смысле ИИ – это научить машины действовать и думать, как люди.
Это создание программ, которые будут сами действовать без участия человека.
Другое направление ИИ связано с тем, чтобы дать машинам больше когнитивных и сенсорных возможностей.
Это направление связано с анализом изображений и видео, с обработкой и пониманием речи и так далее.
Это создание технологий, которые в некоторых случаях могут заменить то, что делают люди.
И это создание приложений для интеллектуального решения проблем с использованием алгоритмов.
Это разработка программ или алгоритмов таким образом, чтобы они могли учиться и совершенствоваться с течением времени под воздействием новых данных.
Таким образом, искусственный интеллект может быть чем-то, что имитирует человеческий интеллект.
Это в широком смысле.
Более узкое направление – это может быть чисто вычислительный подход и подход для оптимизации, в котором производится манипуляция данными таким образом, чтобы получить неочевидные результаты.
И здесь ИИ – это инструмент, который используется компьютером для автоматического выполнения задач практически без вмешательства человека.
ИИ – это сложная серия алгоритмов, которые что-то делают с поступающей информацией.
Мы будем исходить из того, что искусственный интеллект – это набор технологий, который позволяет извлекать знания из данных.
Таким образом, это любая система, которая изучает или понимает шаблоны или закономерности в этих данных и может идентифицировать их, а затем воспроизводить их на новой информации.
Мы будем исходить из того, что искусственный интеллект – это не симулятор человеческого интеллекта, а ИИ – это машинное обучение.
И технология машинного обучения – это использование математики в компьютерах для поиска неких шаблонов или закономерностей в данных.
И эти данные могут быть структурированными или неструктурированными.
Единственное различие между машинным обучением и технологиями, которые были до этого, состоит в том, что раньше нам, людям, приходилось вручную кодировать эти шаблоны.
Но компьютеры могут найти эти шаблоны или закономерности самостоятельно, используя математику.
Таким образом, для нас искусственный интеллект – это набор математических алгоритмов, которые позволяют компьютерам находить шаблоны, о которых мы, возможно, даже не подозреваем, без необходимости кодировать их вручную.
Можно сказать, что ИИ – это все, что заставляет машины действовать более разумно.
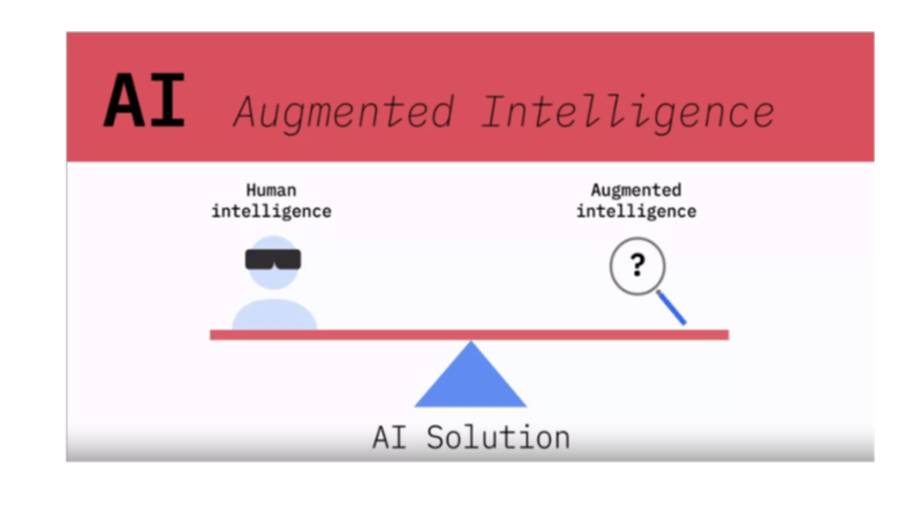
Также можно сказать, что ИИ – это дополненный интеллект.
ИИ не обязательно должен пытаться заменить людей, а скорее должен расширять человеческие возможности и выполнять задачи, которые ни люди, ни просто машины не могут выполнить самостоятельно.
Интернет дал нам быстрый доступ к большему количеству информации.
И сейчас у нас есть распределенные вычисления и интернет вещей, которые также связаны с огромным объемом информации.
И также есть социальные сети, которые генерируют огромный объем неструктурированных данных.
И с помощью ИИ, мы можем взять информацию, которая необходима экспертам, в определенной предметной области, и подкрепить ее доказательствами, чтобы эксперты могли принимать более обоснованные решения.
Вот что такое дополненный интеллект.
С ИИ эксперты могут расширить свои возможности и позволить машинам выполнять трудоемкую работу.
Теперь, как ИИ может учится?
Мы предоставляем машинам возможность исследовать примеры и создавать модели машинного обучения на основе входных данных и желаемых результатов.
И мы можем делать это различными способами, такими как контролируемое обучение, неконтролируемое обучение и дополнительное обучение.
На самом деле у людей есть очень распространенное заблуждение о том, что искусственный интеллект – это человеческий разум внутри компьютера, что человеческий интеллект полностью имитируется в компьютере.
Но машинное обучение или ИИ не моделирует человеческий разум, он просто пытается открыть новые возможности для компьютеров.
ИИ пытается позволить компьютерам понимать определенные виды данных, которые они не могли понять раньше.
Так, например, если посмотреть на то, что могут люди, то мы можем понимать язык, мы обладаем такой сложной способностью общаться на языке.
Также наш мозг может воспринимать колебания молекул воздуха и превращать их в мысли, и это действительно удивительно.
Мы также отлично умеем обрабатывать визуальные данные, например, когда вы смотрите на чье-то лицо, вы можете мгновенно узнать его.
Когда вы смотрите на чьи-то глаза, вы можете точно сказать, куда они смотрят, и это действительно удивительная способность.
Это то, что компьютеры не могут сделать, потому что они фундаментально ограничены математикой.
Они могут понимать только числа и математические операции.
Но, используя технологию машинного обучения, вы можете взять эту математику и использовать ее для изучения шаблонов или закономерностей в огромном объеме как структурированных, так и неструктурированных данных.
Вот что такое сейчас практически для нас ИИ.
Общее использование ИИ в настоящее время заключается в получении больших наборов данных и обработки этих данных в режиме реального времени.
В зависимости от типа решаемых задач, ИИ также можно разделить на типы – узкий, общий и супер.
Узкий ИИ – это ИИ, который применяется к определенной области.
Например, языковые репетиторы, виртуальные помощники, автомобили с автопилотом, поиск в Интернете с помощью ИИ, и так далее.
Узкий ИИ – это тип интеллекта, который хорош только для определенной задачи, хотя и узкие ИИ могут выполнять задачи, на выполнение которых уходит обычному человеку годы.
Узкий ИИ может выполнять конкретные задачи, но не изучать новые, принимая решения на основе запрограммированных алгоритмов и обучающих данных.
И узкий ИИ – это то, что мы уже научились создавать.
Общий ИИ – это ИИ, который может работать с широким спектром независимых и не связанных задач.
Он может изучать новые задачи для решения новых проблем, и он делает это, обучая себя новым стратегиям.
Общий интеллект – это сочетание многих стратегий ИИ, которые учатся на опыте и могут действовать на человеческом уровне интеллекта.
Общий ИИ является типом ИИ, наиболее близким человеческому интеллекту. И общий ИИ может выполнять различные задачи, иногда одновременно, также как и мы.
И сегодня мы приближаемся к созданию общего ИИ.
Хотя компьютеры в миллионы раз лучше нас в анализе и обработке данных, им никогда не удавалось мыслить абстрактно или придумывать оригинальные идеи.
Супер-ИИ или сознательный ИИ – это ИИ с человеческим сознанием на уровне самосознания.
И так как мы сами еще не можем адекватно определить, что такое сознание, маловероятно, что мы сможем создать сознательный ИИ в ближайшем будущем.
ИИ – это слияние многих областей исследования.
Информатика и электротехника определяют, как ИИ реализуется в программном и аппаратном обеспечении.
А математика и статистика определяют модели для него.
Создание ИИ основывается на нашем понимании как работает мозг.
И психология, и лингвистика играют важную роль в понимании того, как ИИ может работать, а философия дает рекомендации по интеллекту и этическим соображениям.
И сегодня мы уже видим примеры того, как ИИ участвует в решениях, которые принимают люди.
И ИИ уже доказал свою полезность в различных областях, оказывающих существенное влияние на жизнь людей и нашего общества.
На протяжении веков электричество считалось делом колдунов – магов, которые оставляли зрителей в недоумении о том, откуда электричество берется.
И когда Бенджамин Франклин доказал связь между электричеством и молнией, он с трудом мог представить его практическое использование в 1752 году.
На самом деле, он считал своим самым ценным изобретением – как избежать электричество – громоотвод.
И все новые инновации проходят аналогичную эволюцию: непонимание, избегание, страх и, наконец принятие.
И в течение многих лет после экспериментов Франклина человек постоянно использовал электричество, хотя ему все еще не хватало глубокого понимания происхождения электричества.
И Справочник по электротехнике 1928 года начинается со строк: «Что такое электричество? – Никто не знает».
Но согласно этому руководству для начинающих электриков, понимание происхождения электричества не было важным.
Более важным аспектом было знание того, как электричество можно генерировать и безопасно использовать для света, тепла и энергии.
Сегодня слишком много людей рассматривают искусственный интеллект как еще одну магическую технологию, которую можно использовать для работы, мало понимая, как она работает.
Они считают ИИ чем-то особенным и относятся к экспертам, которые освоили эту технологию, как к магам.
И ИИ приобрел мистический вид с обещаниями величия и вне досягаемости простых смертных.
Но правда, конечно, в том, что в ИИ нет магии.
Термин «искусственный интеллект» впервые появился в 1956 году, и с тех пор технология прогрессировала, разочаровывала и вновь появлялась.
Как и в случае с электричеством, путь к прорывам в ИИ придет с массовыми экспериментами.
Хотя многие из этих экспериментов потерпят неудачу, успешные будут иметь существенное влияние на развитие технологии.
Можно сказать, что ИИ – это новое электричество.
Помимо того, что ИИ становится повсеместным и все более доступным, ИИ расширяет и меняет методы ведения бизнеса по всему миру.
Он позволяет с высокой точностью прогнозировать и автоматизировать бизнес-процессы и принятие решений.
И его воздействие огромно, начиная от повышения качества обслуживания клиентов и заканчивая интеллектуальными продуктами и более эффективными услугами.
И в итоге результатом будет значительное экономическое влияние на компании, страны и общество.
И безусловно, организации, которые проводят массовые эксперименты в области искусственного интеллекта, получат в дальнейшем конкурентные преимущества.
Согласно исследованиям, в период с настоящего времени до 2030 года на основе ИИ прирост валового продукта составит 16 триллионов долларов США.
Это невиданный ранее масштаб экономического воздействия, и он касается не только ИТ-индустрии, он затрагивает практически на все отрасли и аспекты нашей жизни.
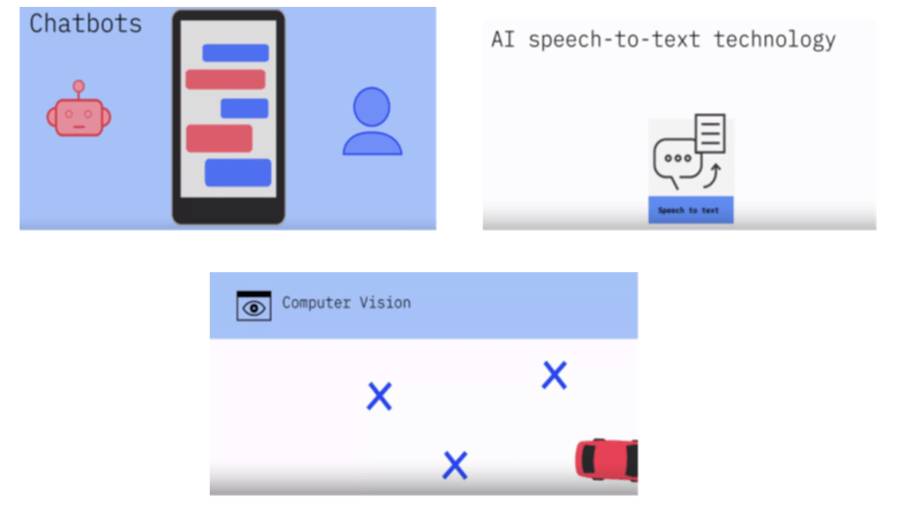
Возможности искусственного интеллекта по языковой обработке не только позволяют машинам и людям понимать и взаимодействовать друг с другом, но и создают новые возможности и новые способы ведения бизнеса.
Чат-боты, использующие возможности языковой обработки, используются в здравоохранении для опроса пациентов и выполнения базовых диагнозов, как настоящие врачи.
В сфере образования они предоставляют студентам онлайн-репетиторов.
Чат-боты обслуживания клиентов улучшают качество обслуживания клиентов, решая вопросы и освобождая время персонала.
Достижения искусственного интеллекта в технологии преобразования речи в текст являются причиной того, что компании используют голос на основе ИИ для повышения качества обслуживания клиентов и придают своему бренду уникальный голос.
Именно благодаря достижениям в области ИИ область компьютерного зрения смогла превзойти людей в задачах, связанных с обнаружением и маркировкой объектов.
Компьютерное зрение является одной из причин, по которой автомобили сами могут двигаться по улицам и избегать столкновений с препятствиями.
Алгоритм компьютерного зрения позволяет обнаружение черт лица и изображений и сравнение их с базами данных.
Это то, что позволяет устройствам аутентифицировать личности своих владельцев с помощью распознавания лиц, позволяет приложениям социальных сетей обнаружение и маркировку пользователей, а также правоохранительным органам выявлять преступников в видеопотоках.
ИИ влияет на качество нашей жизни ежедневно.
ИИ не допускает поступление спама в наши почтовые ящики и напоминает нам о важных событиях.
ИИ работает за сценой.
Он отслеживает наши инвестиции, выявляет мошеннические операции с кредитными картами и предотвращает финансовые преступления.
ИИ дает изменяющие жизнь рекомендации относительно здоровья и финансов, сопоставляет данные, которые могут нарушить конфиденциальность, и многое другое.
Идея искусственного интеллекта не нова и восходит к 1950-м годам.
Но ограничения вычислительной мощности препятствовали развитию этой технологии.
В 90-е годы, получив новый импульс, с развитием вычислительных мощностей, многие технологии, такие как нейронные сети, стали частью ИИ.
11 мая 1997 года мир был покорен, когда IBM Deep Blue победила Гарри Каспарова, действующего чемпиона мира по шахматам.
Мир исследований ИИ взорвался.
К концу 2000-х годов ИИ добился значительного прогресса в развитии технологий, таких как большие данные, Интернет и облачные вычисления, которые превратились в современные приложения искусственного интеллекта во множестве областей.
И компания IBM стала инициатором такой области ИИ как когнитивные вычисления.
Многие считают, что когнитивные вычисления представляют собой новую эру вычислений.
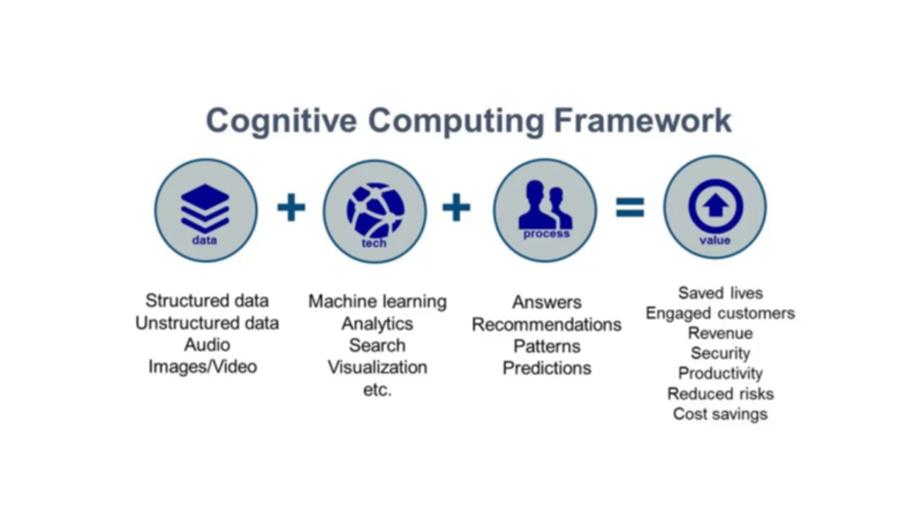
Когнитивные вычисления – это подобласть ИИ.
Когнитивные вычисления используют те же технологии, что и ИИ, такие как машинное обучение, нейронные сети, обработка языка, и так далее, но, чтобы имитировать процессы решения проблем, которые люди выполняют изо дня в день.
Когнитивные вычисления основаны на самообучающихся системах, которые используют методы машинного обучения для интеллектуального выполнения специфических задач, похожих на человеческие.
Узкий искусственный интеллект не пытается имитировать мыслительные процессы человека.
Вместо этого, узкая система ИИ – это сложные алгоритмы для решения конкретной задачи – в случае беспилотной машины, она просто избегает столкновений, держа курс.
И узкий ИИ не пытается обрабатывать те же данные так же, как человеческий мозг.
Но, с другой стороны, когнитивные вычисления не принимают решения за людей, а скорее дополняют наши собственные решения.
Хотя цель когнитивных вычислений – это понять и воспроизвести суть человеческого интеллекта.
Система когнитивных вычислений имеет способность адаптироваться (как мозг) к любому окружению.
Она является динамичной в сборе данных и понимании целей и требований.
И когнитивная система обладает возможностью легко взаимодействовать с пользователями, чтобы пользователи могли легко определять свои потребности.
Аналогично, она также взаимодействует с другими устройствами и облачными сервисами.
Система когнитивных вычислений обладает способностью понимать, идентифицировать и извлекать контекст, такой как синтаксис, время, местоположение, правила, профили, процессы, задачи и цели.
Она опирается на несколько источников информации, включая как структурированную, так и неструктурированную цифровую информацию.
И мы можем найти множество примеров успешных систем когнитивных вычислений.
Например, точность технологии распознавания голоса Google выросла с 84 процентов в 2012 году до 98 процентов менее чем за два года.
Технология DeepFace Facebook теперь может распознавать лица с точностью до 97 процентов.
В настоящее время в сфере когнитивных вычислений доминируют такие крупные игроки, как IBM, Microsoft и Google.
IBM, являясь пионером этой технологии, инвестировала 26 миллиардов долларов в большие данные и аналитику и сейчас тратит около трети своего бюджета на исследования и разработки в области когнитивных вычислений.
IBM Watson – это суперкомпьютер и платформа когнитивных вычислений IBM.
Основная задача Уотсона – понимать вопросы, сформулированные на естественном языке, и находить на них ответы с помощью ИИ.
IBM Watson использует глубокий анализ контента и обоснование на основе фактических данных.
В сочетании с вероятностными методами обработки, Watson может улучшить процесс принятия решений, сократить расходы и оптимизировать результаты.
Microsoft Cognitive Services – это набор API, SDK и когнитивных сервисов, которые разработчики могут использовать для повышения интеллектуальности своих приложений.
С помощью таких сервисов разработчики могут легко добавлять интеллектуальные функции в свои приложения – такие как обнаружение эмоций и чувств, распознавание изображений и речи, знание, поиск и понимание языка.
Машинное обучение, глубокое обучение, нейронные сети
Прежде чем мы углубимся в то, как работает ИИ, и его различные варианты использования и приложения, давайте еще раз вернемся к терминам и концепциям ИИ, и разберем понятия искусственного интеллекта, машинного обучения, глубокого обучения и нейронных сетей.
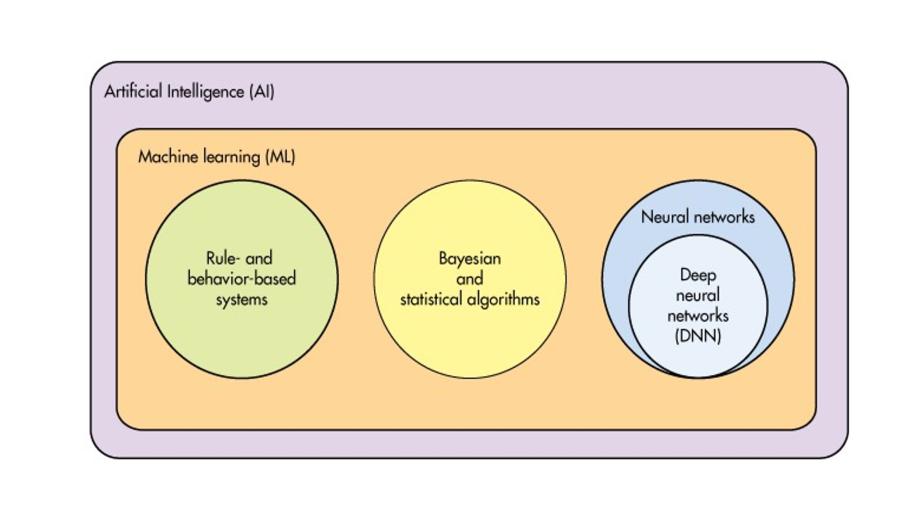
Эти термины иногда используются взаимозаменяемо, но они не относятся к одному и тому же.
Искусственный интеллект – это область информатики, занимающаяся симуляцией интеллектуального поведения.
Системы ИИ, как правило, демонстрируют поведение, связанное с человеческим интеллектом, такое как планирование, обучение, рассуждение, решение задач, представление знаний, восприятие, движение и манипуляция, и в меньшей степени социальный интеллект и креативность.
Машинное обучение – это подмножество ИИ, которое использует компьютерные алгоритмы для анализа данных и принятия разумных решений на основе того, что они узнали, без явного программирования.
Алгоритмы машинного обучения обучаются на больших наборах данных и учатся на примерах.
Они не следуют алгоритмам, основанным на правилах.
Машинное обучение – это то, что позволяет машинам самостоятельно решать задачи и делать точные прогнозы, используя предоставленные данные.
Глубокое обучение – это специализированный раздел машинного обучения, который использует многоуровневые нейронные сети для имитации принятия человеческих решений.
Алгоритмы глубокого обучения могут маркировать и классифицировать информацию и идентифицировать шаблоны – закономерности.
Это то, что позволяет системам искусственного интеллекта постоянно учиться в процессе работы и повышать качество и точность результатов, определяя правильность принятых решений.
Идея искусственных нейронных сетей основывается на биологических нейронных сетях, хотя они работают совсем по-другому.
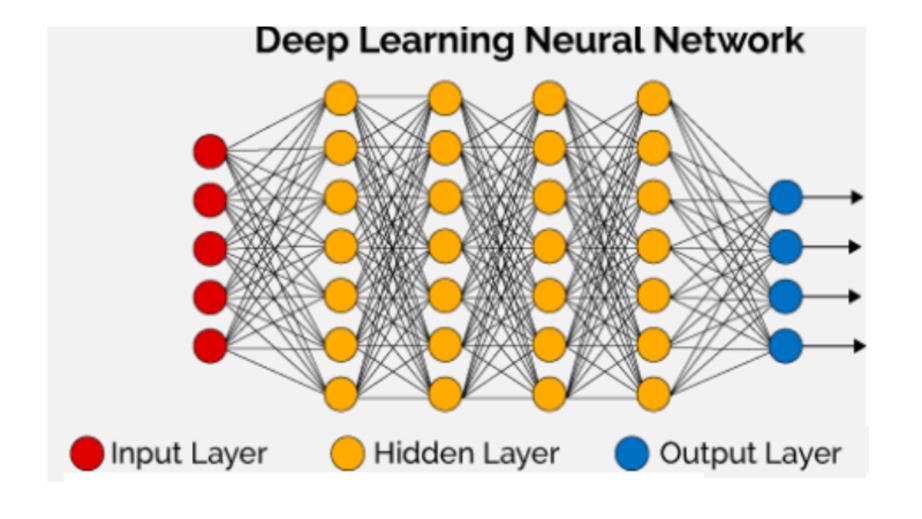
Нейронная сеть в ИИ представляет собой набор небольших вычислительных блоков, называемых нейронами, которые принимают входящие данные и учатся принимать решения с течением времени.
Нейронные сети часто являются многоуровневыми и становятся более эффективными по мере увеличения объема наборов данных, в отличие от других алгоритмов машинного обучения.
Теперь, давайте разберем еще одно важное различие, которое важно понять, – это различие между искусственным интеллектом и наукой о данных.
Наука о данных – это процесс и метод извлечения знаний и идей из больших объемов разнородных данных.
Это междисциплинарная область, включающая математику, статистический анализ, визуализацию данных, машинное обучение и многое другое.
Это то, что позволяет нам обрабатывать информацию, видеть закономерности, находить смысл в больших объемах данных и использовать информацию для принятия решений.
И наука о данных, Data Science может использовать многие методы искусственного интеллекта, чтобы получить представление о данных.
Например, наука о данных может использовать алгоритмы машинного обучения и даже модели глубокого обучения, чтобы извлечь смысл и сделать выводы из данных.
Существует некоторое пересечение между ИИ и наукой о данных, но одно не является подмножеством другого.
Наоборот, наука о данных – это более широкий термин, охватывающий всю методологию обработки данных.
А ИИ включает в себя все, что позволяет компьютерам учиться решать задачи и принимать разумные решения.
И ИИ, и Data Science могут использовать большие данные.
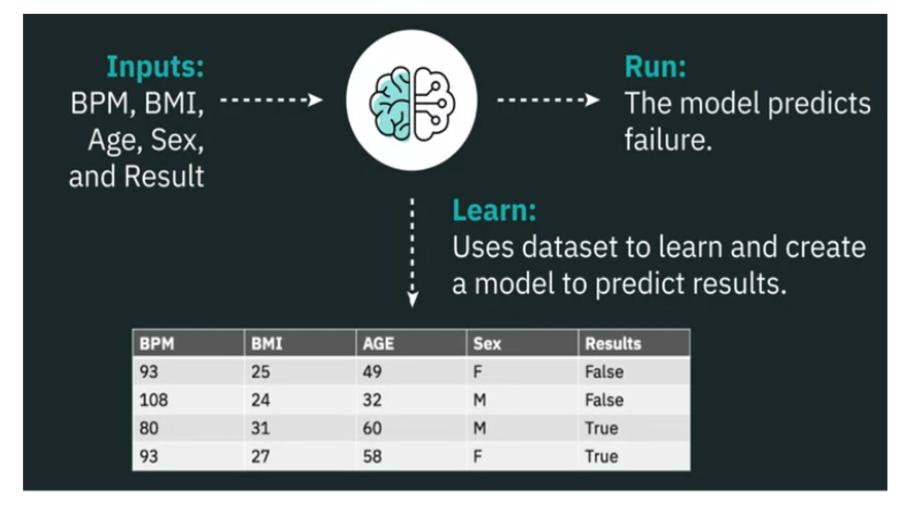
Машинное обучение, подмножество искусственного интеллекта, использует компьютерные алгоритмы для анализа данных и принятия разумных решений на основе того, что алгоритмы изучили.
Вместо того, чтобы следовать алгоритмам, основанным на правилах, машинное обучение само строит модели для классификации и прогнозирования на основе данных.
Например, что, если мы хотим определить, может ли возникнуть проблема с нашим сердцем, с помощью машинного обучения?
Можем ли мы это сделать.
И ответ – да.
Допустим, нам даны такие данные, как количество ударов в минуту, вес тела, возраст и пол.
С машинным обучением и этим набором данных, мы можем изучить и создать модель, которая с учетом входных данных будет предсказывать результаты.
Так в чем же разница между этим подходом и просто использования статистического анализа для создания алгоритма?
Алгоритм – это математическая техника.
В традиционном программировании мы берем данные и правила и используем их для разработки алгоритма, который даст нам ответ.
В этом примере, если бы мы использовали традиционный алгоритм, мы бы взяли данные, такие как сердечный ритм, возраст, вес тела и пол и использовали эти данные для создания алгоритма, который определит, будет ли сердце работать нормально или нет.
По сути, это было бы выражение if – else.
Когда мы отправляем входные данные, мы получаем ответы, основанные на том, какой алгоритм мы определили, и этот алгоритм не изменится от данных.
Машинное обучение, с другой стороны, берет данные и ответы и уже потом само создает алгоритм.
Вместо того, чтобы получить ответы в конце, у нас уже есть ответы.
А то, что мы получаем здесь, – это набор правил, определяющих модель машинного обучения.
И эта модель определяет правила и оператор if – else при получении входных данных.
И эта модель, в отличие от традиционного алгоритма, может постоянно обучаться и использоваться в будущем для прогнозирования значений.
Машинное обучение опирается на определение правил путем изучения и сравнения больших наборов данных, чтобы найти общие закономерности.
Например, мы можем создать программу машинного обучения с большим объемом изображений птиц, и обучить модель возвращать название птицы всякий раз, когда мы даем изображение птицы.
Когда для модели отображается изображение птицы, она маркирует изображение с некоторой степенью достоверности.
Этот тип машинного обучения называется контролируемым обучением, где алгоритм обучается на данных, размеченных человеком.
Чем больше примеров мы предоставляем контролируемому алгоритму обучения, тем точнее он производит классификацию новых данных.
Неуправляемое обучение, это еще один тип машинного обучения, которое основывается на предоставлении алгоритму неразмеченных данных и позволяет ему самостоятельно находить шаблоны.
Вы предоставляете просто входные данные, и позволяете машине делать выводы и находить шаблоны.
Этот тип обучения может быть полезен для кластеризации данных, когда данные группируются в соответствии с тем, насколько они похожи на своих соседей и отличаются от всего остального.
Как только данные кластеризованы, можно использовать различные методы для изучения этих данных и поиска шаблонов.
Например, можно создать алгоритм машинного обучения с постоянным потоком сетевого трафика и позволить ему независимо изучать активность в сети – базовый уровень, нормальную сетевую активность, а также выбросы и, возможно, злонамеренное поведение, происходящее в сети.
Третий тип алгоритма машинного обучения, обучение с подкреплением, это алгоритм машинного обучения с набором правил и ограничений и позволяет ему учиться достигать целей.
Вы определяете состояние, желаемую цель, разрешенные действия и ограничения.
И алгоритм выясняет, как достичь цели, пробуя различные комбинации разрешенных действий, и его награждают или наказывают в зависимости от того, было ли решение правильным.
Алгоритм изо всех сил старается максимизировать свои вознаграждения в рамках предусмотренных ограничений.
И вы можете использовать обучение с подкреплением, чтобы научить машину играть в шахматы или преодолеть какие-либо препятствия.
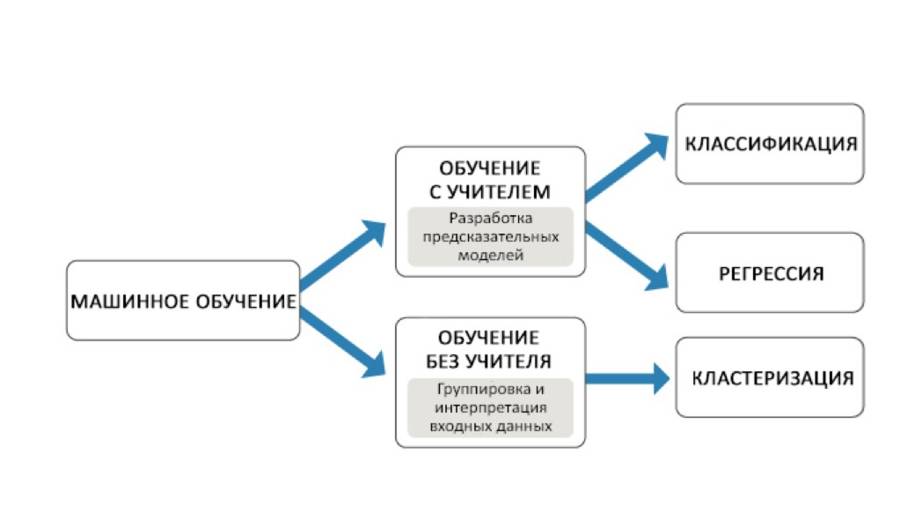
Таким образом, машинное обучение – это широкая область, и мы можем разделить его на три разные категории: контролируемое обучение, неконтролируемое обучение и обучение с подкреплением.
И есть много разных задач, которые мы можем решить с помощью них.
В контролируемом обучении, в наборе данных есть метки, и мы используем их для построения модели классификации данных.
Это означает, что, когда мы получаем данные, у них есть метки, которые говорят о том, что представляют эти данные.
В примере с сердцем, у нас была таблица с метками, это сердечный ритм, возраст, пол и вес.
И каждой такой метке соответствовали значения.
При неконтролируемом обучении у нас нет меток, и мы должны обнаружить эти метки в неструктурированных данных.
И такие вещи обычно делаются с помощью кластеризации.
Обучение с подкреплением – это другое подмножество машинного обучения, и оно использует вознаграждение для наказания за плохие действия или вознаграждение за хорошие действия.
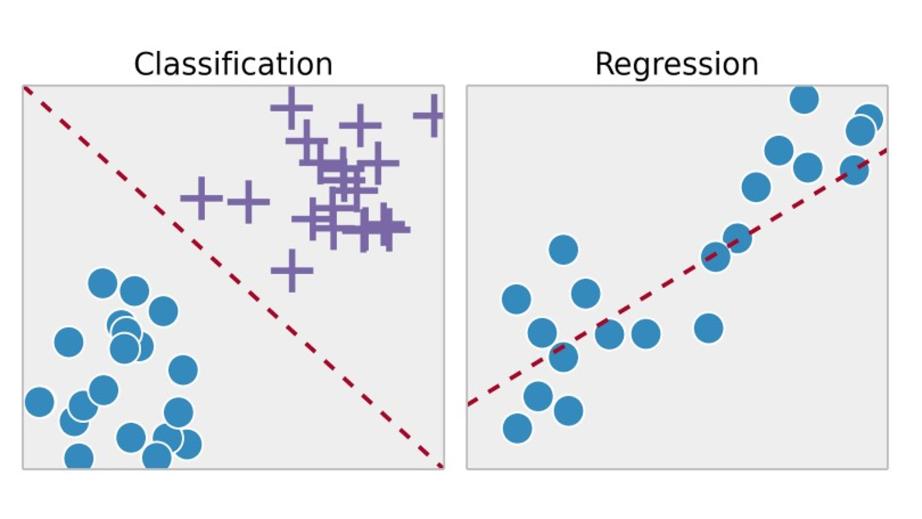
И мы можем разделить контролируемое обучение на три категории: регрессия, классификация и нейронные сети.
Модели регрессии строятся с учетом взаимосвязей между признаками x и результатом y, где y – непрерывная переменная.
По сути, регрессия оценивает непрерывные значения.
Нейронные сети относятся к структурам, которые имитируют структуру человеческого мозга.
Классификация, с другой стороны, фокусируется на дискретных значениях, которые она идентифицирует.
Мы можем назначить дискретные результаты y на основе многих входных признаков x.
В примере с сердцем, учитывая набор признаков x, таких как удары в минуту, вес тела, возраст и пол, алгоритм классифицирует выходные данные y как две категории: истина или ложь, предсказывая, будет ли сердце работать нормально или нет.
В других классификационных моделях мы можем классифицировать результаты по более чем двум категориям.
Например, прогнозирование, является ли данный рецепт рецептом индийского, китайского, японского или тайского блюда.
И с помощью классификации мы можем извлечь особенности из данных.
Особенности в этом примере сердцем, это сердечный ритм или возраст.
Особенности – это отличительные свойства шаблонов ввода, которые помогают определить категории вывода.
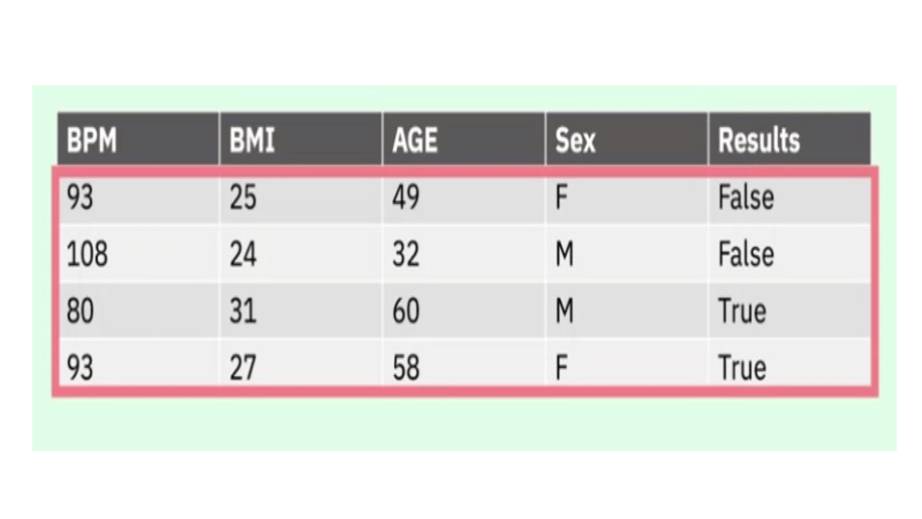
Здесь каждый столбец является особенностью, а каждая строка – точкой ввода данных.
Классификация – это процесс прогнозирования категории заданных точек данных.
И наш классификатор использует обучающие данные, чтобы понять, как входные переменные относятся к этой категории.
Что именно мы подразумеваем под обучением?
Обучение подразумевает использование определенного алгоритма обучения для определения и разработки параметров модели.
Хотя для этого есть много разных алгоритмов, с точки зрения непрофессионала, если вы тренируете модель, чтобы предсказать, будет ли сердце работать нормально или нет, есть истинные или ложные значения, и вы будете показывать алгоритму некоторые реальные данные, помеченные как истинные, затем снова показывая данные, помеченные как ложные, и вы будете повторять этот процесс с данными, имеющими истинные или ложные значения.
И алгоритм будет изменять свои внутренние параметры до тех пор, пока он не научится распознавать данные, которые указывают на то, что есть сердечная недостаточность или ее нет.
При машинном обучении мы обычно берем набор данных и делим его на три набора: наборы обучения, проверки и тестирования.
Набор обучения – это данные, используемые для обучения алгоритма.
Набор проверки используется для проверки наших результатов и тонкой настройки параметров алгоритмов.
Данные тестирования – это данные, которые модель никогда не видела прежде и которые используются для оценки того, насколько хороша наша модель.
Опять же, чтобы повторить, модель машинного обучения – это алгоритм, используемый для поиска закономерностей в данных без программирования в явном виде.
В то время как машинное обучение является подмножеством искусственного интеллекта, глубокое обучение является специализированным подмножеством машинного обучения.
Глубокое обучение основывается на алгоритмах машинного обучения, которые основываются на структуре и функциях мозга, и эти алгоритмы называются искусственными нейронными сетями.
Эти сети предназначены для непрерывного обучения в процессе работы для повышения качества и точности результатов.
Эти системы могут обучаться на неструктурированных данных, таких как фотографии, видео и аудиофайлы.
Алгоритмы глубокого обучения напрямую не отображают входные данные в выходные.
Вместо этого они полагаются на несколько слоев обработки.
Каждый такой слой передает свой вывод следующему слою, который обрабатывает его и передает его следующему.
Именно поэтому такая система из многочисленных слоев называется глубоким обучением.
При создании алгоритмов глубокого обучения разработчики и инженеры настраивают количество слоев и тип функций, которые соединяют выходы каждого слоя со входами следующего.
Затем они обучают модель, предоставляя множество размеченных примеров.
Например, вы даете алгоритму глубокого изучения тысячи изображений и метки, которые соответствуют содержанию каждого изображения.
Алгоритм будет запускать эти примеры через свою многоуровневую нейронную сеть и будет подгонять веса переменных в каждом слое нейронной сети, чтобы иметь возможность обнаруживать общие шаблоны, которые определяют изображения с похожими метками.




