



Тимур Машнин
Машинное обучение и Искусственный Интеллект
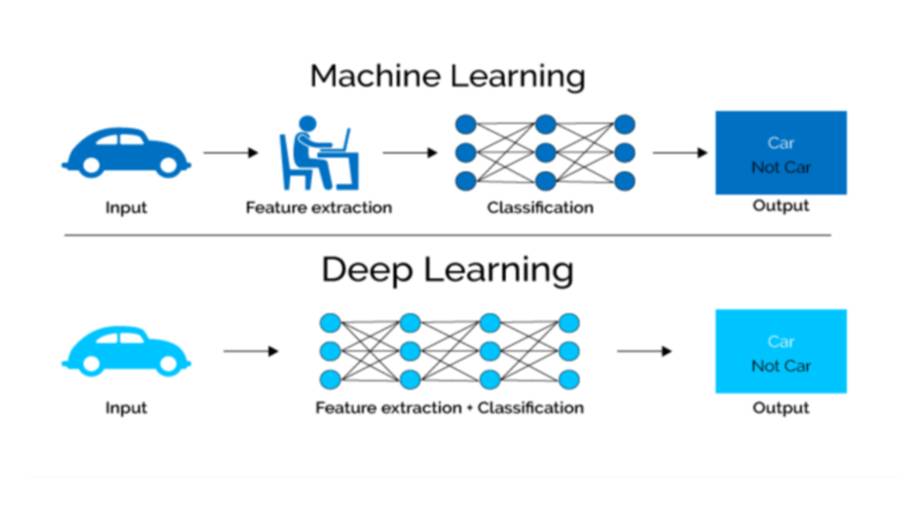
Глубокое обучение устраняет одну из основных проблем, с которой сталкивались алгоритмы обучения предыдущего поколения.
В то время как эффективность и производительность алгоритмов машинного обучения предыдущего поколения не улучшалась по мере роста наборов данных, алгоритмы глубокого обучения продолжают улучшаться по мере поступления большего количества данных.
Глубокое обучение оказалось очень эффективным при выполнении различных задач, включая распознавание и транскрипцию голоса, распознавание лиц, медицинскую визуализацию и языковой перевод.
Глубокое обучение также является одним из основных компонентов беспилотных автомобилей.
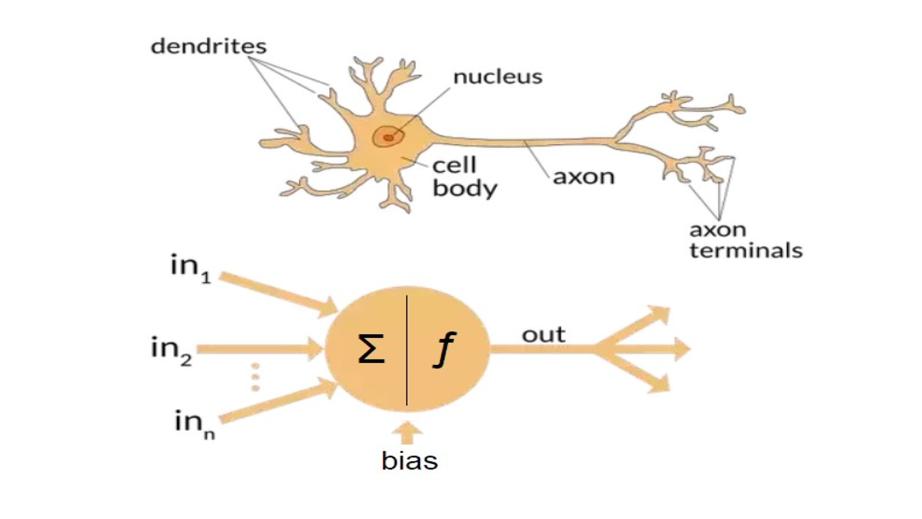
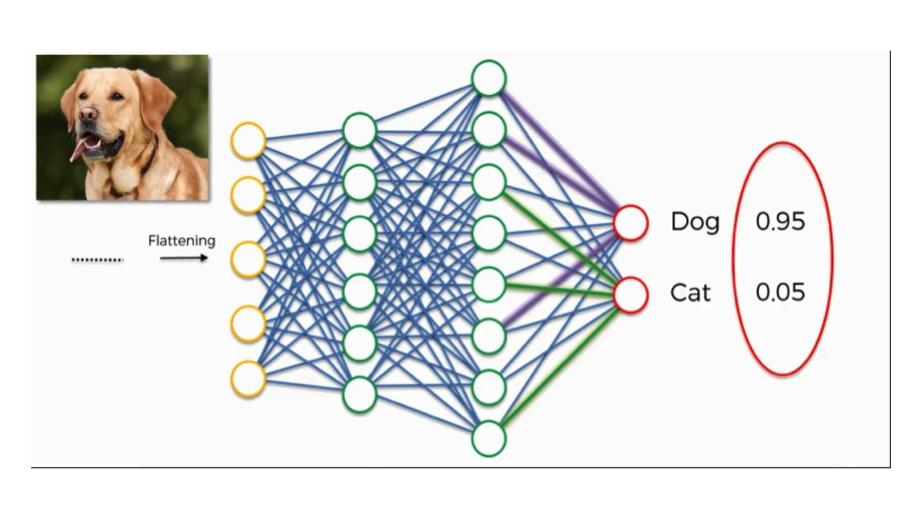
Искусственная нейронная сеть представляет собой совокупность мелких единиц, называемых нейронами, которые представляют собой вычислительные единицы, смоделированные по способу обработки информации человеческим мозгом.
Искусственные нейронные сети заимствуют некоторые идеи из биологической нейронной сети мозга, чтобы приблизить некоторые результаты его обработки.
Эти единицы или нейроны принимают поступающие данные, также как и биологические нейронные сети, и со временем учатся принимать решения.
Нейронные сети учатся через процесс, называемый обратным распространением.
Например, при преобразовании речи в текст, в нейронных сетях вместо кодирования правил вы предоставляете образцы голоса и соответствующий им текст.
И нейронная сеть находит общие шаблоны произношения слов, а затем учится сопоставлять новые голосовые записи с соответствующими им текстами.
YouTube использует это для автоматического создания субтитров.
Обратное распространение использует набор обучающих данных, которые сопоставляют известные входы с желаемыми выходами.
Сначала входы подключаются к сети и определяются выходы.
Затем функция ошибки определяет, насколько далеко данный выход находится от желаемого выхода.
И наконец, делаются изменения, чтобы уменьшить ошибки.
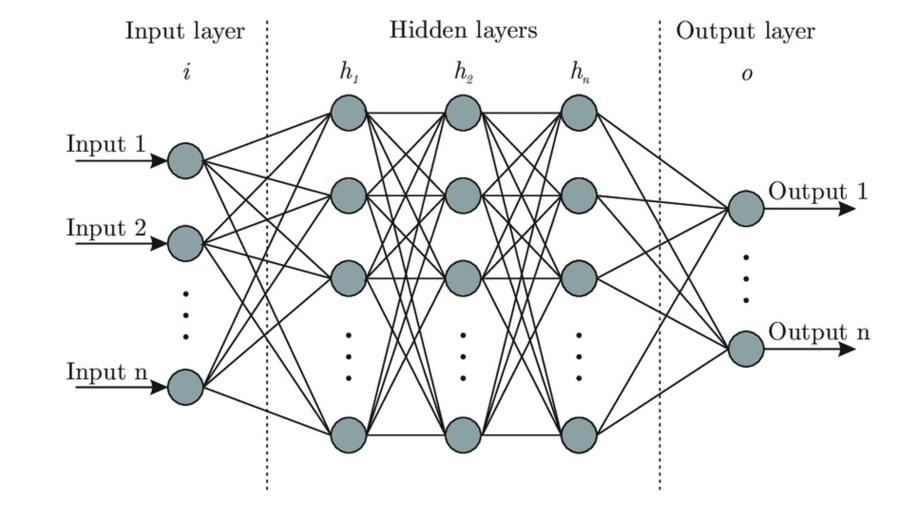
Набор нейронов называется слоем, и слой принимает входные данные и обеспечивает выходные данные.
Любая нейронная сеть будет иметь один входной слой и один выходной слой.
И нейронная сеть также будет иметь один или несколько скрытых слоев, которые имитируют типы деятельности, происходящих в человеческом мозге.
Скрытые слои принимают набор взвешенных входных данных и выдают результат с помощью функции активации.
Нейронная сеть, имеющая более одного скрытого слоя, называется глубокой нейронной сетью.
Перцептроны – это самые простые и старые типы нейронных сетей.
Это однослойные нейронные сети, состоящие из входных узлов, подключенных непосредственно к выходному узлу.
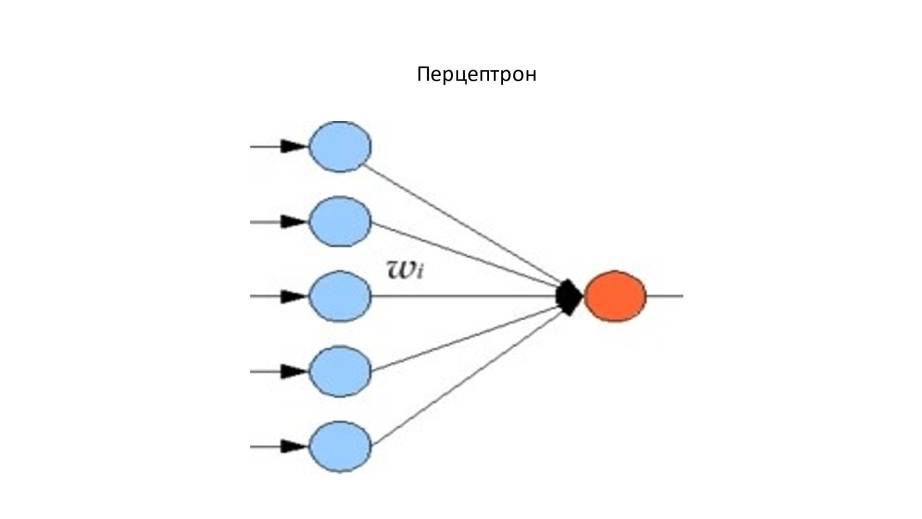
Входные слои передают входные значения следующему слою путем умножения на вес и суммирования результатов.
Скрытые слои получают входные данные от других узлов и направляют свои выходные данные на другие узлы.
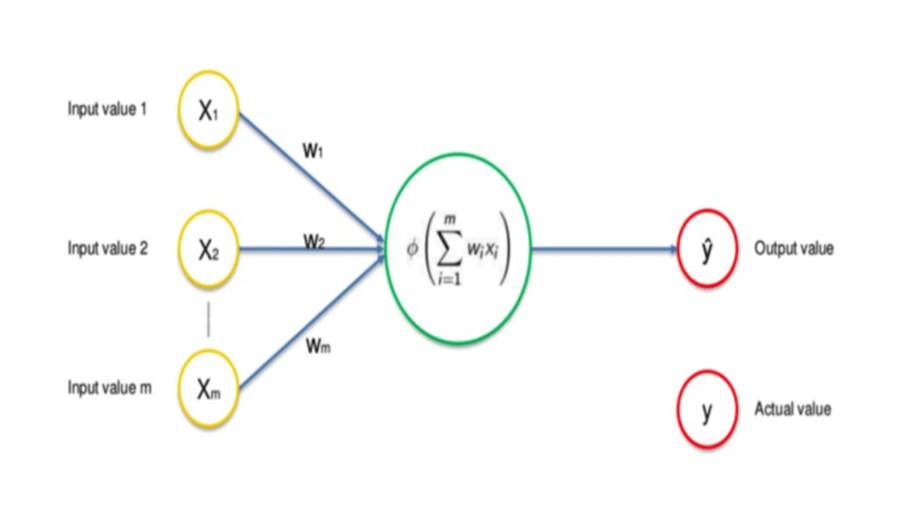
Скрытые и выходные узлы имеют свойство, называемое смещением bias, которое представляет собой особый тип веса, который применяется к узлу после рассмотрения других входных данных.
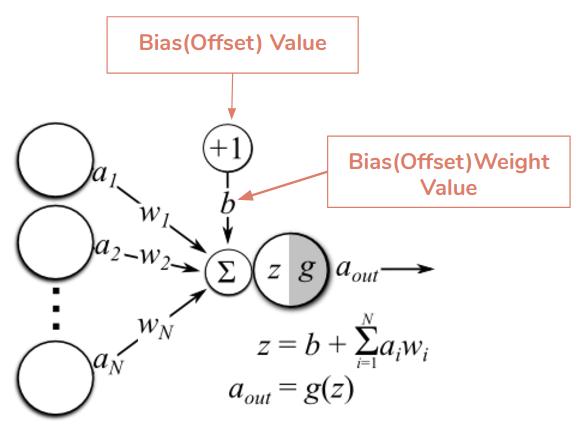
И наконец, функция активации определяет, как узел реагирует на свои входные данные.
Функция запускается на сумме входов и смещения, а затем результат передается как выходной.
Функции активации могут принимать различные формы, и их выбор является критическим компонентом успеха нейронной сети.
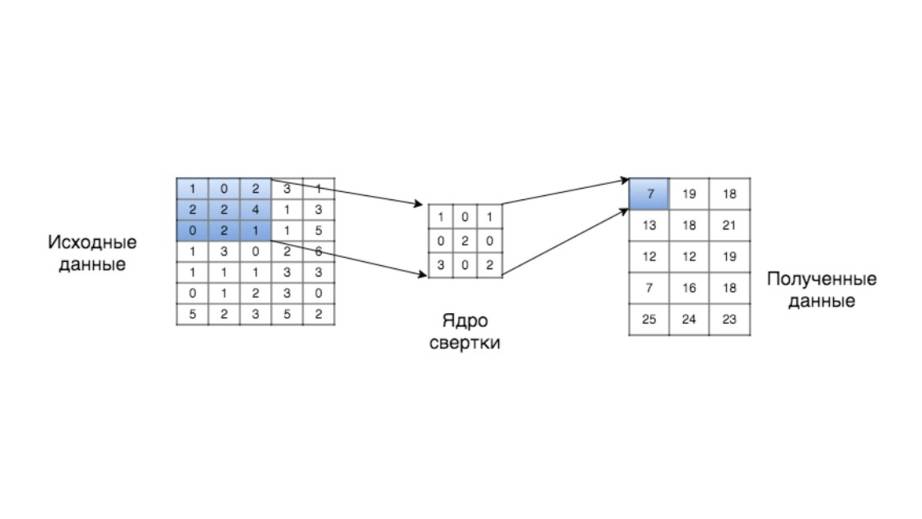
Сверточные нейронные сети или CNN представляют собой многослойные нейронные сети, которые основываются на работе зрительной коры животных.
CNN полезны в таких приложениях, как обработка изображений, распознавание видео и обработка языка.
Свертка – это математическая операция, в которой функция применяется к другой функции, а результат представляет собой смесь двух функций.
Свертки хороши при обнаружении простых структур на изображении и объединении этих простых функций для создания более сложных функций.
В сверточной сети этот процесс происходит в последовательности слоев, каждый из которых проводит свертку на выходе предыдущего слоя.
CNN являются экспертами в построении сложных функций из менее сложных.

Рекуррентные нейронные сети или RNN являются рекуррентными, потому что они выполняют одну и ту же задачу для каждого элемента последовательности, причем предыдущие выходы питают входы последующих этапов.
В обычной нейронной сети вход обрабатывается через несколько слоев, а выход создается с допущением, что два последовательных входа независимы друг от друга, но это может не выполняться в определенных сценариях.
Например, когда нам нужно учитывать контекст, в котором было произнесено слово, в таких сценариях необходимо учитывать зависимость от предыдущих наблюдений, чтобы получить результат.
И RNN могут использовать информацию в длинных последовательностях, причем каждый уровень сети представляет наблюдение в определенное время.
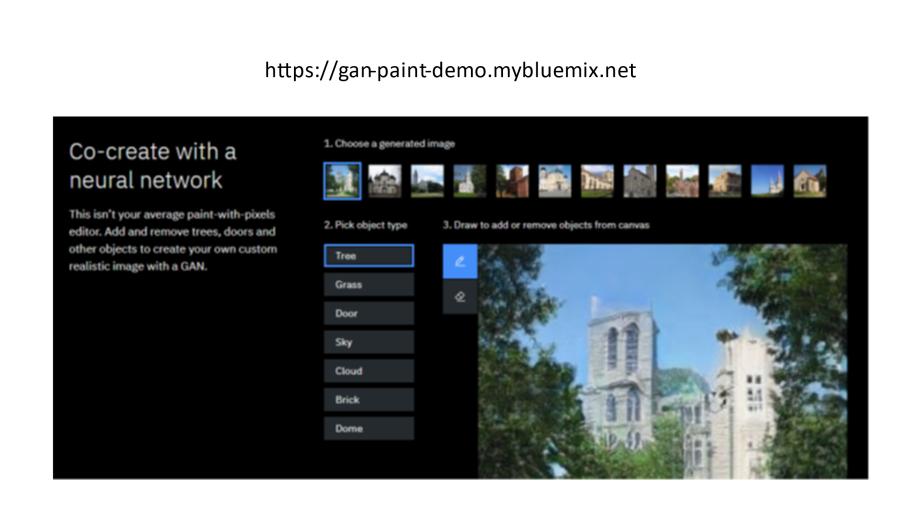
Новый тип нейронной сети, называемый порождающей состязательной сетью (GAN), может использоваться для создания сложных выходных данных, таких как фотореалистичные изображения.
На странице сайта IBM вы можете попробовать создать изображение с помощью GAN.
В разделе «Совместное создание с нейронной сетью» в разделе «Выберите сгенерированное изображение» выберите одно из существующих изображений.
И в списке Pick object type выберите тип объекта, который вы хотите добавить.
Например, нажмите на дерево.
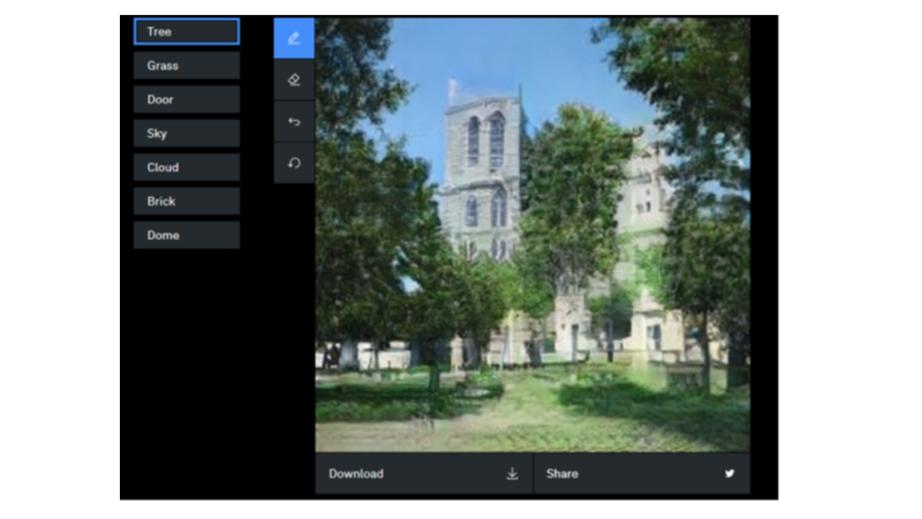
Переместите курсор на изображение.
Нажмите и удерживая кнопку мыши нажатой, наведите курсор на область существующего изображения, в которую вы хотите добавить объект, в данном случае дерево.
Выберите другой тип объекта и добавьте его к изображению.
Поэкспериментируйте: можете ли вы поместить дверь в небо?
И используйте функции отмены и удаления, чтобы удалить объекты.
И нажмите «Загрузить», чтобы сохранить свою работу.
Наука о данных
Наука о данных – это процесс использования данных, чтобы понять различные вещи, понять мир.
Это когда у вас есть модель или гипотеза проблемы, и вы пытаетесь проверить эту гипотезу или модель на данных.
Наука о данных – это искусство раскрытия идей и тенденций, которые скрываются за данными.
Данные реальны, данные имеют реальные свойства, и нам нужно изучить их, если мы собираемся работать с ними.
Это название появилось в 90-х годах, когда некоторые профессора вели учебную программу по статистике, и они подумали, что было бы лучше назвать это наукой о данных.
Но что такое наука о данных?
Если у вас есть данные, и вы работаете с данными, и вы манипулируете ими, вы исследуете их, сам процесс анализа данных, в попытках получить ответы на какие-то вопросы, – это наука о данных.
И наука о данных актуальна именно сегодня, потому что у нас есть огромный объем доступных данных.
Раньше стоял вопрос о нехватке данных.
Теперь у нас есть непрерывные потоки данных.
В прошлом у нас не было алгоритмов работы с данными, теперь у нас есть алгоритмы.
Раньше программное обеспечение было дорогим, теперь оно с открытым исходным кодом и бесплатное.
Раньше мы не могли хранить большие объемы данных, теперь за небольшую плату мы можем иметь доступ к большим наборам данных.
Теперь, как соотносятся между собой ИИ, машинное обучение и наука о данных.
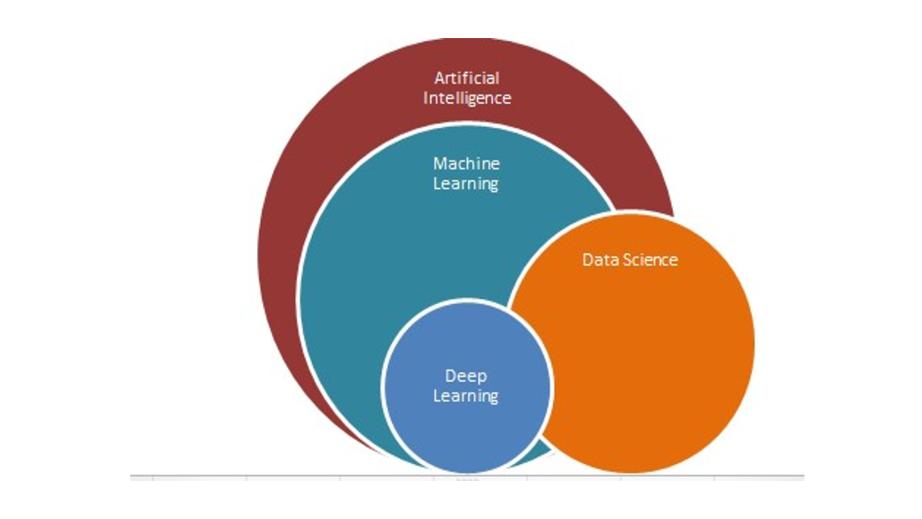
Искусственный интеллект – это очень широкий термин для различных применений: от робототехники до анализа текста.
Это все еще развивающаяся технология, и есть вопросы о том, должны ли мы на самом деле стремиться к высокоуровневому ИИ или нет.
Машинное обучение – это подмножество искусственного интеллекта, которое фокусируется на узком диапазоне видов деятельности.
Фактически это единственный вид искусственного интеллекта, который сейчас существует с некоторыми приложениями в реальных задачах.
Наука о данных не является подмножеством машинного обучения, но использует машинное обучение для анализа данных и прогнозирования будущего.
Наука о данных сочетает в себе машинное обучение с другими дисциплинами, такими как анализ больших данных и облачные вычисления.
Наука о данных – это практическое применение машинного обучения с фокусом на решении реальных задач.
Наука о данных в основном сосредоточена на работе с неструктурированными данными.
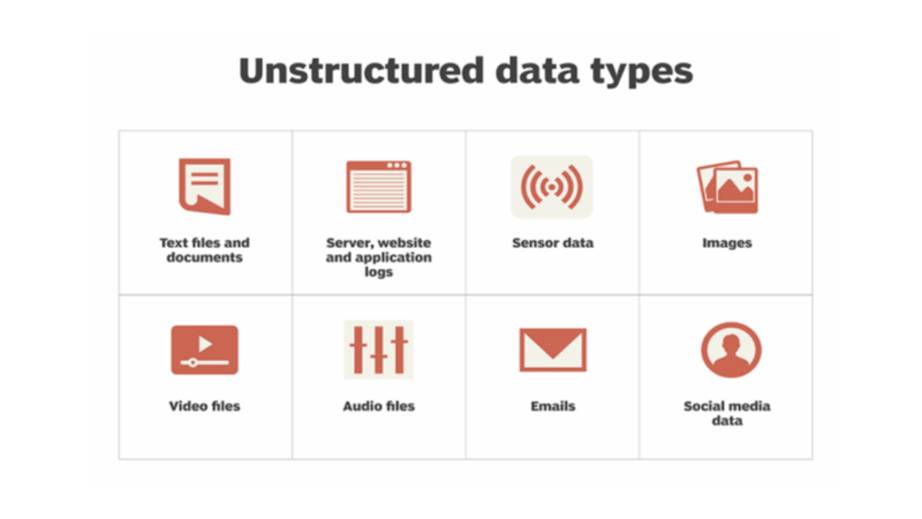
Структурированные данные больше похожи на табличные данные, с которыми мы имеем дело в Microsoft Excel, где у вас есть строки и столбцы, и это называется структурированными данными.
Неструктурированные данные – это данные, поступающие в основном из Интернета, где они не являются табличными, они не в виде строк и столбцов, а в виде текста, иногда это видео и аудио, поэтому вам придется использовать более сложные алгоритмы для обработки этих данных.
Традиционно при вычислении и обработке данных мы переносим данные на компьютер.
Но если данных очень много, они просто могут не поместиться на одном компьютере.
Поэтому Google придумал очень просто: они взяли данные и разбили их на куски, и они отправили эти куски файлов на тысячи компьютеров, сначала это были сотни, а потом тысячи, и теперь десятки тысяч компьютеров.
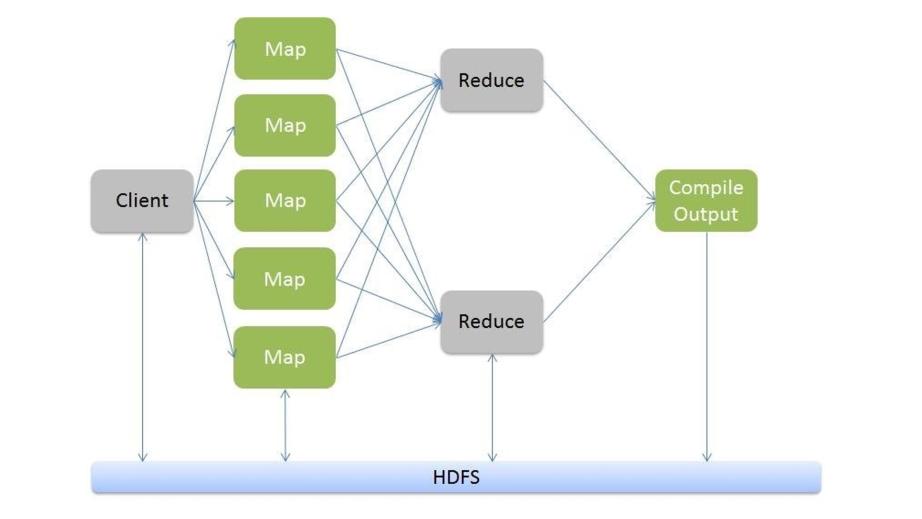
И они поставили одну и ту же программу на все эти компьютеры в кластере.
И каждый компьютер запускает эту программу на своем маленьком фрагменте файла и отправляет результаты обратно.
Затем результаты сортируются и объединяются.
Первый процесс называется процессом Map, а второй – процессом Reduce.
Это довольно простые концепции, но оказалось, что вы можете делать с их помощью много разных видов обработки, выполнять много разных задач и обрабатывать очень большие наборы данных.
И такая архитектура называется Hadoop.
И когда у нас появились вычислительные возможности для обработки данных, у нас появились новые методы, такие как машинное обучение.
С помощью которого мы можем взять большие наборы данных, и вместо того, чтобы брать выборку из этих данных и пытаться проверить какую-то гипотезу, мы можем взять большие наборы данных и искать в них шаблоны – закономерности.
То есть перейти от проверки гипотез к поиску шаблонов, которые, возможно, будут генерировать гипотезы.
Это отличается от традиционной статистики, где у вас должна быть гипотеза, которая не зависит от данных, и затем вы проверяете ее на данных.
В машинном обучении сами данные генерируют гипотезы.
С появлением больших данных и вычислительных возможностей стало актуальным глубокое машинное обучение и использование нейронных сетей.
Jupyter Notebook
Технология нейронных сетей существовала 30 лет назад, но ее развитие сдерживалось нехваткой данных и вычислительных возможностей.
Нейронные сети – это попытка подражать нейронам мозга и тому, как на самом деле функционирует наш мозг.
Нейронная сеть получает некоторые входные данные, которые затем передаются в разные узлы обработки, которые выполняют некоторые преобразования в данных, а затем передают результаты на другой уровень узлов и, наконец, сеть выдает конечный результат.
Таким образом, нейронная сеть представляет собой компьютерную программу, которая имитирует, как наш мозг использует нейроны.
Нейронная сеть содержит входы и выходы, и вы продолжаете вводить данные в эти входы, и смотрите на выходы, и вы продолжаете делать это снова и снова, таким образом, чтобы эта сеть давала нужные результаты, при этом регулируя преобразования внутри сети.
Так вы обучаете нейронную сеть.
И теперь у нас есть нейронные сети и глубокое обучение, которые могут распознавать речь и распознавать людей.
И глубокое обучение требует больших вычислительных мощностей, так что это не то, что вы можете делать на своем ноутбуке, вы можете поиграть с нейронной сетью, но, если вы действительно хотите сделать что-то серьезное, у вас должен быть доступ к специальным вычислительным ресурсам.

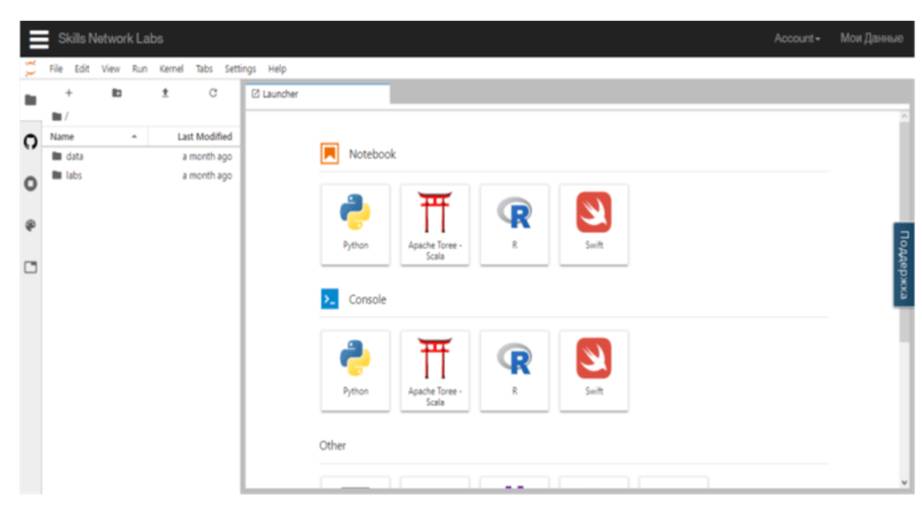
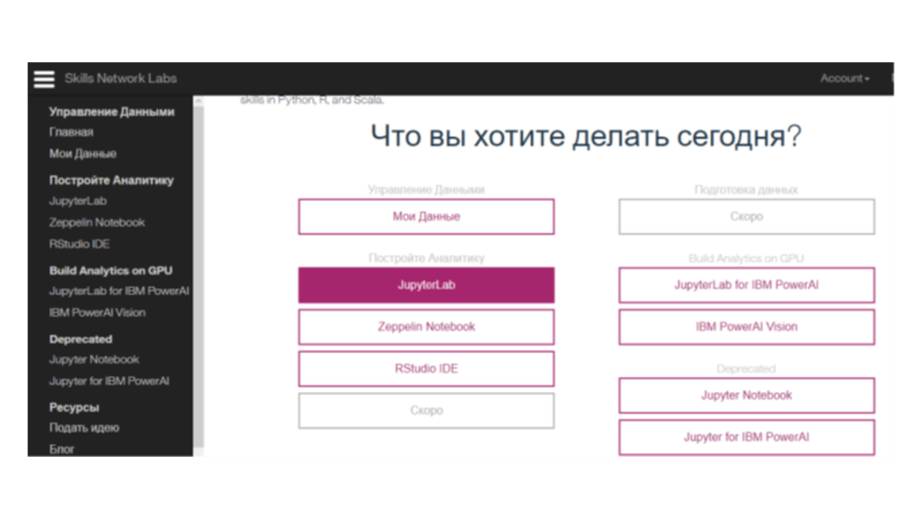
Теперь, для обучения работе с данными существуют бесплатные инструменты, например, Skills Network Labs от компании IBM.
Это бесплатная виртуальная лабораторная среда, которая позволяет практиковаться и изучать науку о данных.
Skills Network Labs содержит такие инструменты, как RStudio, Jupyter и Zeppelin.
И эти инструменты предоставляют интерактивную среду для анализа данных, визуализации данных, машинного обучения и распознавания изображений.
Например, кнопка JupyterLab откроет собой интерактивную среду, которая позволяет запускать или создавать записные книжки notebook, которые запускают коды на Python с помощью Jupyter Notebooks, Scala на Apache Toree и R.
Jupyter Notebook – это веб-приложение, в котором вы можете создавать и обмениваться документами, содержащими живой код, уравнения, визуализации, а также текст.
И Jupyter Notebook является одним из инструментов, помогающих приобрести необходимые навыки в области науки о данных.
Что такое Jupyter Notebook?
В данном случае «записная книжка» notebook означает документ, который содержат как код, так и элементы форматированного текста, такие как рисунки, ссылки, уравнения и так далее.
И из-за такого сочетания кода и текста, эти документы являются идеальным местом собрать воедино описание анализа данных и его результаты, а также возможность выполнить анализ данных в режиме реального времени.
И приложение Jupyter Notebook создает такие документы.
«Jupyter» является аббревиатурой, означающей Julia, Python и R.
Эти языки программирования были первыми языками, которые поддерживал Jupyter, но в настоящее время технология Jupyter также поддерживает другие языки, на которых можно писать код в Jupyter.
Таким образом, документы notebook – это документы, созданные приложением Jupyter Notebook, которые содержат как компьютерный код (например, python), так и элементы форматированного текста (абзацы, уравнения, рисунки, ссылки и т. д.).
Документы notebook – это читаемые документы, содержащие описание анализа и результаты анализа данных (рисунки, таблицы и т. д.), а также исполняемый код, который можно запустить для анализа данных.
Что такое приложение Jupyter Notebook?
Это клиент-серверное приложение, которое позволяет редактировать и запускать записные книжки notebook через веб-браузер.
Приложение Jupyter Notebook может быть запущено на компьютере без доступа к Интернету или установлено на удаленном сервере, где вы можете получить к нему доступ через Интернет.
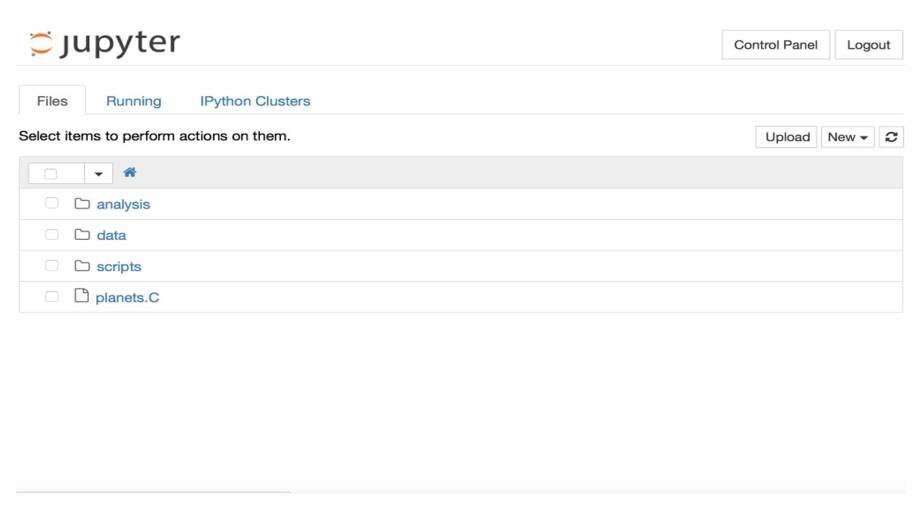
Помимо отображения, редактирования и запуска записных книжек, в приложении Jupyter Notebook есть «Панель инструментов» (Notebook Dashboard), отображающая локальные файлы и позволяющая открывать записные книжки и останавливать их ядра.
Ядро – это программа, которая запускает код, написанный в записной книжке.
Приложение Jupyter Notebook имеет ядро ipython для кода Python, но также есть ядра, доступные для других языков программирования.
Когда вы открываете документ Notebook, соответствующее ядро запускается автоматически.
И ядро выполняет вычисления и выдает результаты.
Теперь, как появился Jupyter Notebook.
В 2001 году, программист Фернандо Перес начинает разработку IPython – интерактивную оболочку для языка программирования Python.
И в 2005 году и Роберт Керн, и Фернандо Перес попытались создать систему для ноутбуков.
К сожалению, прототип ноутбука так и не стал полностью пригодным для использования.
Но команда IPython продолжала работать, и в 2007 году они сделали еще одну попытку внедрения системы типа ноутбуков.
К октябрю 2010 года появился прототип веб-ноутбука, и в 2011 года этот прототип был реализован.
И наконец, в 2014 году проект Jupyter был запущен как отдельный проект от проекта IPython.
И IPython – теперь одно из ядер Jupyter.
И теперь появилось новое поколение ноутбуков Jupyter, которые называются JupyterLab.
Теперь, как возникла эта идея ноутбуков.
Концепция ноутбука, который содержит обычный текст и расчеты и графику, была не новой.
Фернандо Перес был активным пользователем ноутбуков Mathematica, которые были созданы в качестве графического интерфейса в 1988 году Теодором Греем, основателем компании Wolfram Research – частная компания, занимающаяся производством математического программного обеспечения. Её основным продуктом является среда технических расчётов Mathematica.
И сочетание этой идеи ноутбуков с технологией AJAX веб-приложений, которая не требует от пользователей обновления веб страницы каждый раз, когда изменяются ее данные, дало старт разработке ноутбуков Jupyter.

Для установки Jupyter на свой компьютер, рекомендуется установить Анаконду, которая установит Python, Jupyter Notebook и другие часто используемые пакеты для научных вычислений и обработки данных.
Anaconda – это бесплатный дистрибутив языков программирования Python и R для научных вычислений с открытым исходным кодом, где пакетами управляет инструмент conda, а не pip.

Как альтернатива, вы можете установить только Jupyter с помощью инструмента pip.
И после установки, вы можете запустить Jupyter на своем компьютере с помощью команды jupyter notebook.

Эта команда запустит сервер ноутбука и откроет веб страницу интерфейса Jupyter по адресу http://localhost:8888/.
И здесь вы увидите Панель управления записными книжками.
Закрытие браузера или его вкладки не приведет к закрытию приложения Jupyter Notebook.
Чтобы полностью закрыть приложение, необходимо закрыть соответствующий терминал, где вы запустили Jupyter.
Так как приложение Jupyter Notebook – это сервер, который отображается в вашем браузере по адресу http://localhost:8888.
И закрытие браузера не приведет к выключению сервера.
Вы можете снова открыть адрес, и приложение Jupyter Notebook будет отображено заново.
Вы можете запустить много копий приложения Jupyter Notebook, и они будут отображаться по адресу localhost только с разными портами.
И так как с помощью одного приложения Jupyter Notebook вы уже можете открывать множество записных книжек, не рекомендуется запускать несколько копий приложения Jupyter Notebook.
Во вкладке Files веб страницы Jupyter показываются все ваши файлы, во вкладке Running показываются все процессы ноутбуков, а третья вкладка Clusters предоставляется параллельной вычислительной средой IPython.
Чтобы создать новый ноутбук, нужно нажать на кнопку New во вкладке «Файлы».

И здесь вы можете создать обычный текстовый файл, папку и терминал.
Также вы можете создать ноутбук на Python 3.
Начнем сначала с создания обычного текстового файла.
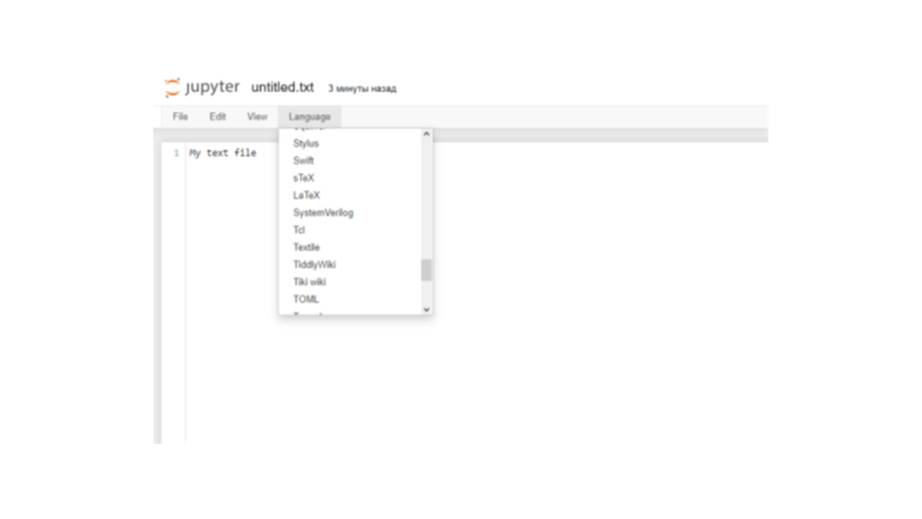
Когда он откроется, вы увидите, что это похоже на любой другой текстовый редактор.
Здесь вы можете указать язык программирования, на котором вы пишете.
Также, вы можете сохранить, переименовать или загрузить файл или создать новый файл.
Вы также можете создавать папки, чтобы организовать ваши документы.
Для этого нажмите Folder в меню New, и у вас появится новая папка.
Далее вы сможете переименовать эту папку.
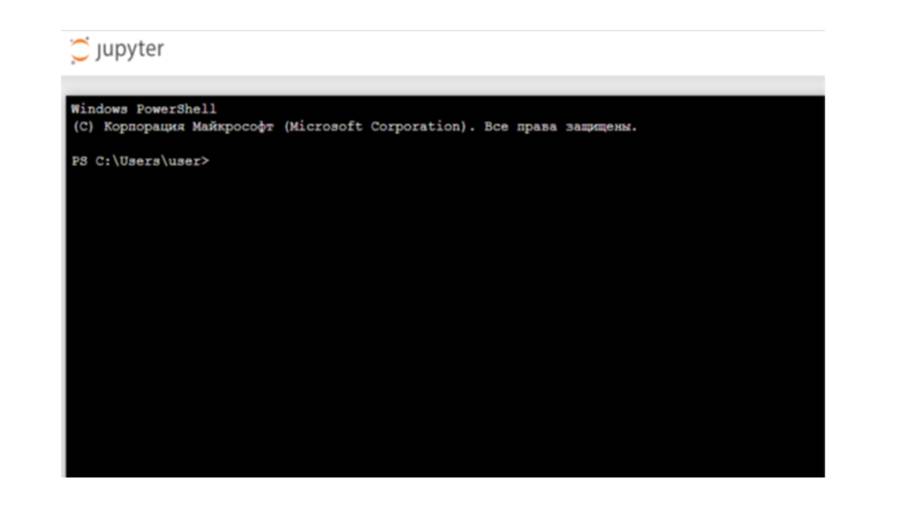
Что касается терминала, терминал предназначен для поддержки сеансов интерактивного терминала на основе веб браузера.
И этот терминал работает так же, как терминал операционной системы или приложение cmd.
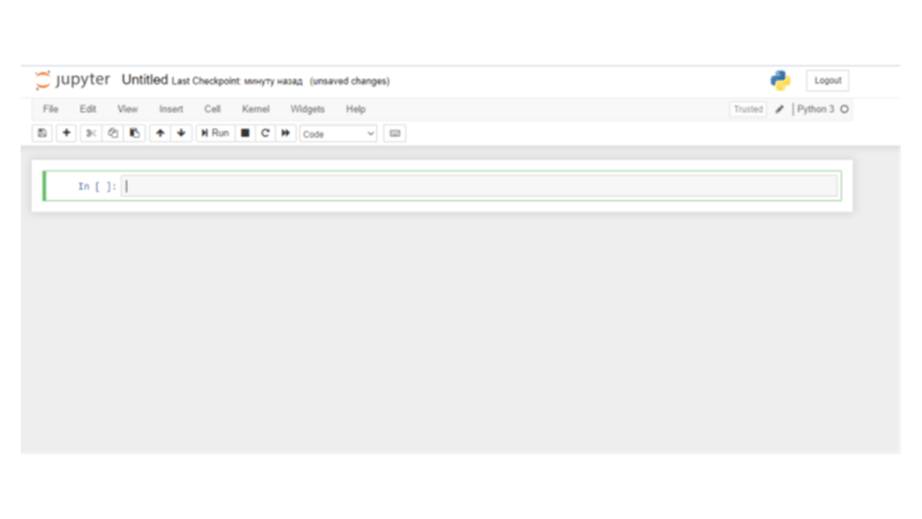
Если же вы хотите запустить свой ноутбук, вернитесь в главное меню и выберите опцию Python 3 в меню New.
Здесь вы увидите строку меню, панель инструментов и пустую ячейку кода.
И в этой ячейке кода вы можете сразу начать с импорта необходимых библиотек для вашего кода.
После этого вы можете добавлять, удалять или редактировать ячейки кода, вставляя пояснительный текст и заголовки.
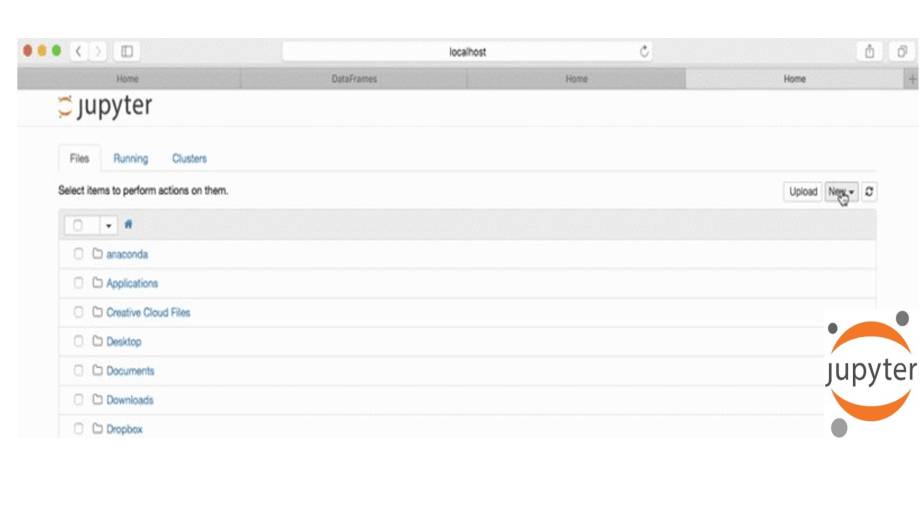
После создания ноутбука, вы можете использовать меню «Файл», чтобы загрузить свою записную книжку в виде HTML, PDF, и так далее.
Вместо настольной версии, вы можете использовать среду Skills Network Labs от IBM.
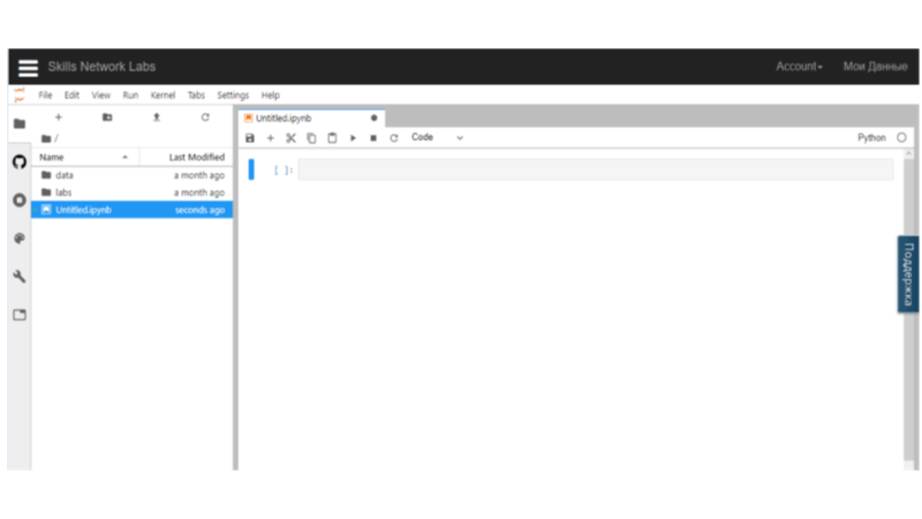
Здесь вы можете открыть JupyterLab – среду, которая позволяет создавать и редактировать блокноты Jupyter.
Когда вы откроете JupyterLab, вы увидите, что с левой стороны у вас есть каталог с файлами, где вы можете отслеживать все ваши файлы, а с правой стороны – экран запуска.
С помощью этого запуска вы можете создавать новые записные книжки Jupyter с Python 3, Scala или R.
Давайте создадим записную книжку с Python 3.

Ноутбуки Jupyter состоят исключительно из ячеек.
Сейчас в этой записной книжке, есть только одна ячейка.
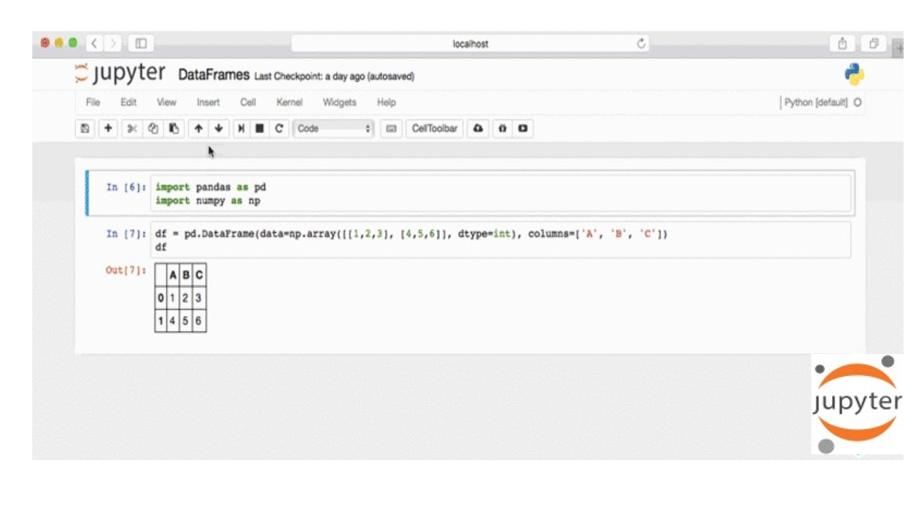
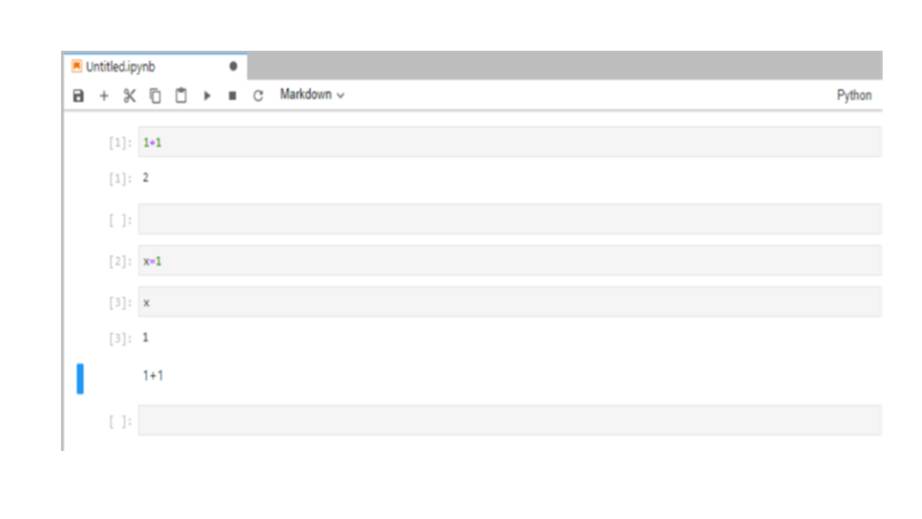
Давайте напишем что-нибудь внутри ячейки, например, 1 + 1, а затем на клавиатуре нажмем Shift + Enter.
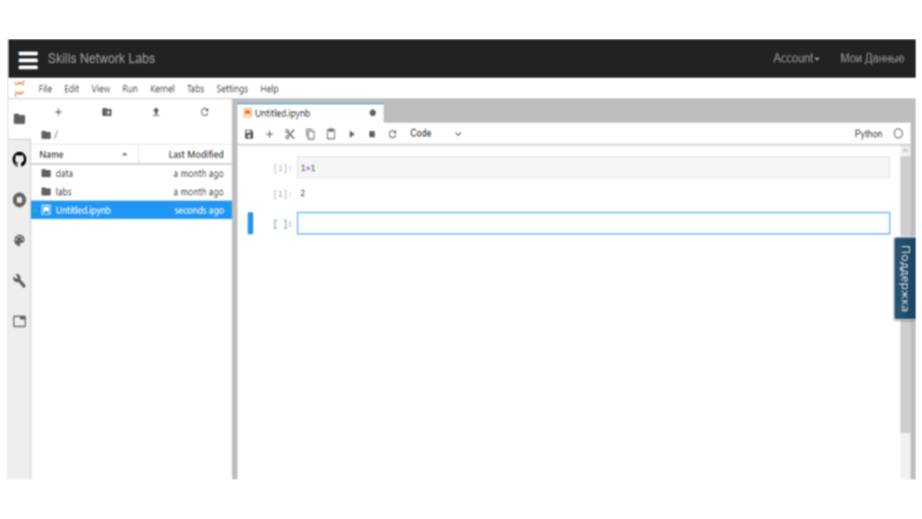
В результате выполнится код с использованием Python, который вернет два.
Далее мы можем создать еще больше ячеек, нажав кнопку «Плюс» вверху, и написать больше кода.
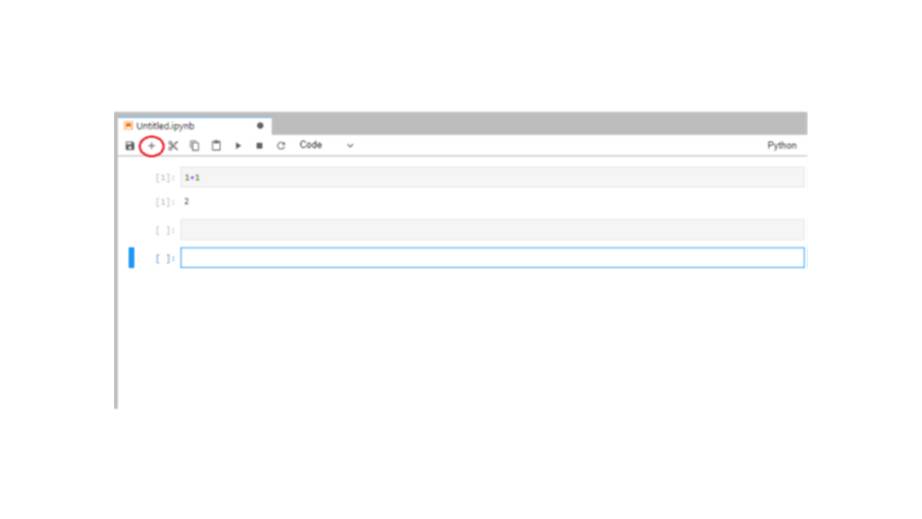
Например, установив X равным целому числу, и распечатать вывод X в ячейке ниже.
И все эти ячейки являются так называемыми ячейками кода, которые позволяют запускать код с использованием интерпретатора, в данном случае Python 3.
Но как мы можем добавить заголовки или текст в нашу записную книжку?
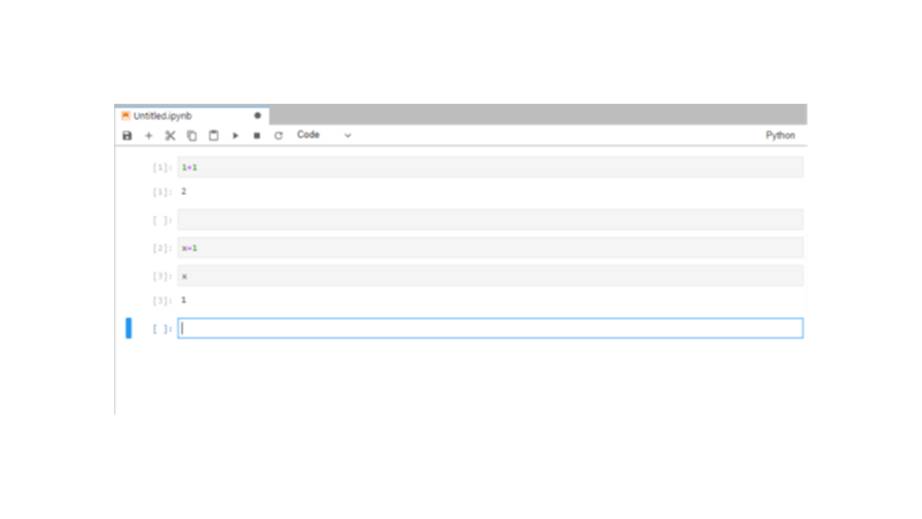
Для этого нужно преобразовать тип ячейки из кода в ячейку markdown, щелкнув на ячейке, и выбрав markdown в меню.
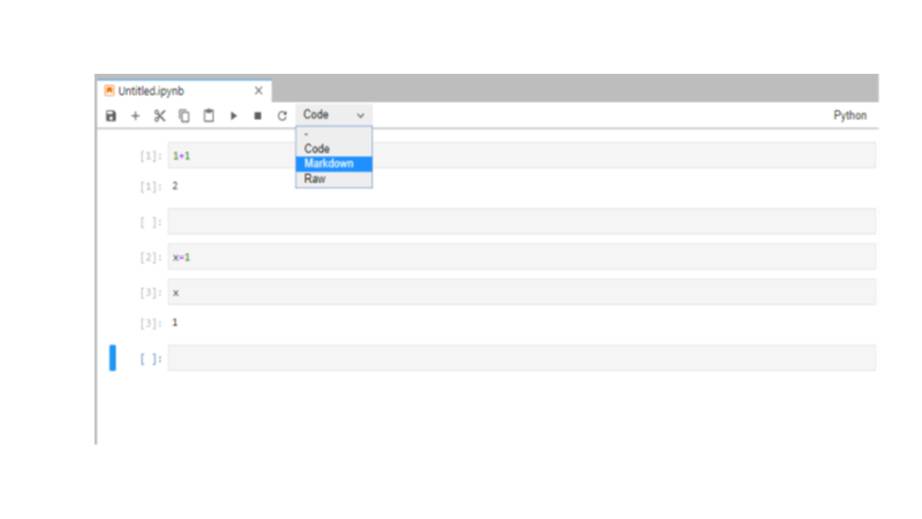
И теперь, если вы введете что-то вроде «один плюс один» в эту ячейку и попытаетесь запустить ее с помощью Shift + Enter, она будет преобразована непосредственно в текст.
И чтобы отредактировать ячейку снова, просто дважды щелкните по ячейке.
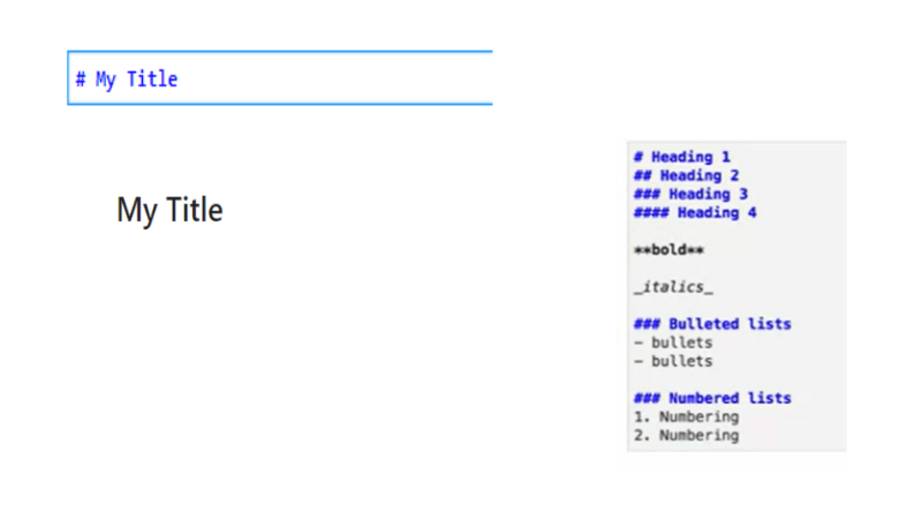
markdown – это разметка, с помощью которой вы можете стилизовать ваш текст.
Например, вы можете создавать заголовки, используя символ решетки и пробел, за которым следует некоторый текст, такой как «Мой заголовок».
Есть и другие способы стилизовать ваш текст.
И здесь показаны несколько примеров.
В ячейках markdown вы также можете использовать HTML.
Например, если вы хотите встроить изображение.
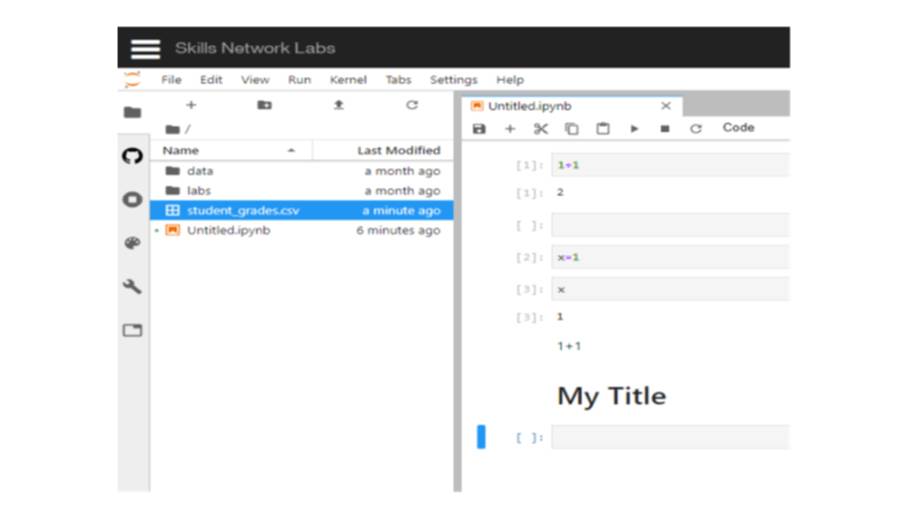
В JupyterLab вы можете импортировать данные, например в виде CSV-файла, и использовать их в блокноте Jupyter.
Чтобы импортировать данные, вы можете просто перетащить файл данных прямо в каталог файлов с левой стороны.
После завершения загрузки он будет отображаться в каталоге.
И это не обязательно должен быть файл CSV, это может быть файл любого типа.
Вы также можете создавать различные папки для организации всех ваших файлов.
И вы можете дважды щелкнуть файл, чтобы открыть предварительный просмотр его содержимого.
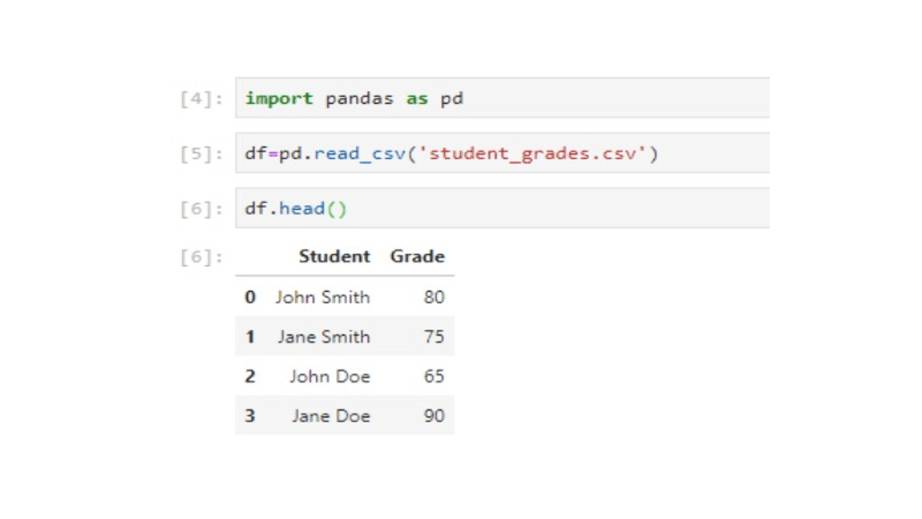
Для обработки данных файла CSV в Python нам нужно использовать функцию чтения CSV библиотеки pandas.
Поэтому сначала импортируем панду.
Затем вы можете прочитать файл, используя путь к файлу CSV.
Теперь, вы можете распечатать первые пять строк файла CSV.




